TaskFlow
修订日期: 2021年6月1日,作者:Johnsom
目录
- 1 概要
- 2 为什么
- 3 设计
- 4 范式转变 (Paradigm shifts)
- 5 最佳实践 (Best practices)
- 6 架构 (Architectures)
- 7 过去、现在和未来 (Past & present & future)
- 8 示例 (Examples)
- 9 核心贡献者(过去和现在) (Core contributors (past and present))
- 10 会议 (Meeting)
- 11 加入我们! (Join us!)
- 12 联系我们! (Contact us!)
- 13 博客/教程/视频/幻灯片 (Blogs/tutorials/videos/slides)
- 14 代码 (Code)
总结

TaskFlow 是一个用于 OpenStack(和其他项目)的 Python 库,旨在使任务执行变得简单、一致、可扩展和可靠。它允许创建轻量级的 task 对象和/或函数,并将它们组合成以声明式方式构建的 flows(又名:工作流)。它包括用于以可以停止、恢复和安全回滚的方式运行这些 flows 的 engines。使用此库实现的工程可以享受增加的状态弹性、自然的声明式构建、更易于测试性(因为 task 只做一件事情)、工作流可插拔性、容错能力以及简化的 崩溃恢复/容错(以及更多)。
概念示例
这个伪代码说明了对于熟悉 SQL 事务的人来说,flow 的工作方式。
START TRANSACTION task1: call nova API to launch a server || ROLLBACK task2: when task1 finished, call cinder API to attach block storage to the server || ROLLBACK ...perform other tasks... COMMIT
上述 flow 可以被 Heat(例如)用作编排的一部分,以添加带有附加块存储的服务器。它可能会启动多个这样的实例以并行准备多个相同的服务器(或者根据所需的请求执行其他工作)。
为什么
OpenStack 代码是自然生长的,并且没有标准和一致的方法来执行一系列代码,以便在调用进程意外终止时可以安全地恢复或回滚代码。大多数项目甚至不尝试使任务可重启或可回滚。存在许多未被跳过或无法在当今代码中实现恢复场景的故障场景。TaskFlow 使解决这些问题变得容易。
目标: 随着 TaskFlow 的广泛使用,OpenStack 即使在未部署高可用性配置的情况下也能变得非常可预测和可靠。
示例用例
服务停止/升级/重启(随时)
OpenStack 项目提供的运行时组件中的一个典型问题是,如果守护进程被强制停止(这通常发生在软件升级、硬件故障、维护期间以及其他操作原因时),会发生什么情况(以及守护进程正在积极执行的状态)。
service stop [glance-*, nova-*, quantum...]
目前,许多 OpenStack 组件没有以一种使系统状态保持可调和状态的方式处理这种强制停止。通常,服务正在积极执行的操作会被立即强制停止,无法恢复,并且在某种程度上被遗忘(后续的扫描过程可能会尝试清理这些孤立的资源)。TaskFlow 将通过跟踪操作、任务及其相关状态来帮助解决这种情况,以便在重新启动服务(即使在服务软件升级后)时,服务可以轻松恢复(或回滚)中断的任务。这有助于鼓励容错架构,避免孤立资源,并有助于减少进一步的守护进程尝试进行清理相关工作的需求(这些守护进程通常会定期激活并导致网络或磁盘 I/O,即使没有需要执行的工作)。
孤立资源
由于缺乏事务语义,许多 OpenStack 项目会留下孤立状态(或处于 ERROR 状态)的资源。如果 OpenStack 将由自动化系统(例如 Heat)驱动,这将是不可接受的,这些系统将无法分析需要清理哪些孤儿。Taskflow 通过提供其面向任务的模型,将能够使用语义来正确跟踪资源修改。这将允许对资源(或一组资源)所做的所有操作以自动化的方式撤消;确保没有资源被遗留。
指标和历史记录
当 OpenStack 服务被构建成 task 和 flow 对象和模式时,它们自动获得添加 metric 报告和操作 history 到使用 taskflow 服务的能力的优势,只需让 taskflow 记录与运行 task 和 flow 相关的指标/历史记录即可。在各种 OpenStack 服务中,目前有多种实现类似功能的方法,但通过自动使用 taskflow,这些方法可以统一为适用于所有 OpenStack 服务的方法(并且使用 taskflow 的开发人员不必担心 taskflow 如何记录此信息)。这有助于解耦与运行 task 和 flow 代码相关的指标和历史记录与定义 task 和 flow 操作的实际代码。
进度/状态跟踪
在许多 OpenStack 项目中,都尝试显示项目正在执行的操作的进度。不幸的是,这种实现方式在各个项目中各不相同,从而导致不一致且不太准确的进度/状态报告和/或跟踪。TaskFlow 可以通过提供一个低级机制来帮助解决这个问题,通过让您插入 TaskFlow 的内置通知系统,可以更轻松(更简单)地跟踪进度。这避免了向操作添加侵入性代码,因为添加对操作不关键的代码会使操作更难理解、调试和审查。它还通过解耦状态/进度跟踪与执行操作/s 的代码来使您的进度/状态机制对未来的更改具有弹性。
其他...
您的用例在这里!
设计
大局观
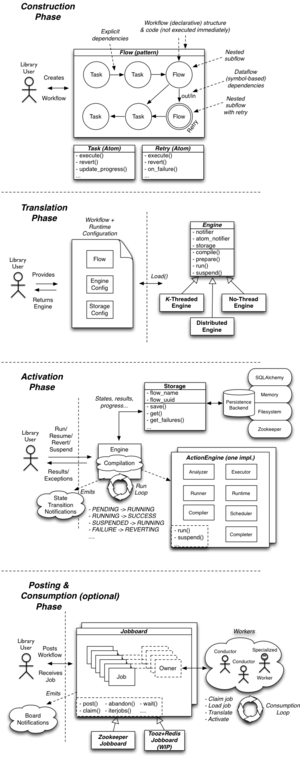
结构
原子 (Atoms)
atom 是 taskflow 中的最小单元。一个 atom 作为其他类别的基础(以避免重复的功能)。并且 atom 预计会命名其期望的输入值/要求,以及其输出/提供的价值以及它自己的名称和版本(如果适用)。
请参阅: atoms 以获取更多详细信息。
タスク
一个 task(从 atom 派生)是具有关联的执行和回滚序列的最小工作单元。
请参阅: tasks 以获取更多详细信息。
重试 (Retries)
一个 retry(从 atom 派生)是控制流程执行的单元。它处理流程失败并可以(例如)使用新参数重试流程。
请参阅: retry 以获取更多详细信息。
流程 (Flows)
一个 flow 是一个将一个或多个 tasks 链接在一起的有序序列的结构。当一个 flow 回滚时,它会通过使用任务定义的任何还原机制来执行其子 tasks 的每个任务的回滚代码。
请参阅: flows 以获取更多详细信息。
模式
也称为: 你如何以编程方式构建要完成的工作(通过任务和流程)。
- 线性 (Linear)
- 描述: 以串行方式一个接一个地运行任务/流程列表。
- 约束: 前置任务的输出必须满足后续任务的输入。
- 用例: 此模式对于结构化任务/流程非常有用,这些任务/流程相对简单,其中一个任务/流程遵循前一个任务/流程。
- 优点: 简单。
- 缺点: 串行,没有并发潜力。
- 无序 (Unordered)
- 描述: 以任何顺序运行一组任务/流程。
- 用例: 此模式对于相对简单且通常是 令人尴尬地并行 的任务/流程非常有用。
- 约束: 不允许任务间依赖关系。
- 优点: 简单。本质上是并发的。
- 缺点: 不允许依赖关系。由于缺乏可靠的排序,跟踪和调试更困难。
- 图表
- 描述: 运行由任务/流程组成的图(节点集合以及这些节点之间的边),以依赖驱动的顺序。
- 约束: 依赖驱动,没有循环。在任务运行之前,保证任务的依赖项已得到满足。
- 用例: 此模式允许非常高的潜在并发度,对于可以安排为有向无环图(没有循环)的任务非常有用。当其依赖项满足时,图中每个独立的任务(或独立的子图)都可以并行运行。
- 优点: 允许复杂的任务排序。可以通过并行运行不相交的任务/流程自动实现并发。
- 缺点: 复杂。不支持循环。由于图依赖关系遍历,跟踪和调试更困难。
注意: 以上任何组合都可以组合在一起(即,将线性模式添加到图形模式中,反之亦然)是有效的。
请参阅: patterns 以获取更多详细信息。
引擎 (Engines)
也称为: 你的任务如何从 PENDING 变为 FAILED/SUCCESS。 它们的目标是可靠地执行你想要的工作流程,并处理围绕使之成为可能的控制和执行流程。这使得使用 taskflow 的代码只需要担心形成工作流程,而不必担心执行、回滚或如何恢复(以及更多!)。
请参阅: engines 以获取更多详细信息。
工作
也称为: 如何为你的任务和流程提供高可用性和可扩展性,确保无论机器承受多少崩溃或故障,都能取得进展(允许你的工作流程承受打击并继续运转)。这个概念使得使用 taskflow 的代码不必担心工作流程的分布或高可用性(开发人员不必担心的事情又少了一项!)。
请参阅: jobs 以获取有关作业(和关联的作业板)机制和概念的更多详细信息。
调度器 (Conductors)
也称为: 将各种概念插入到单个易于使用的运行时单元中的方式。
请参阅: conductors 以获取更多详细信息。
状态 (States)
也称为: 流程(以及其中的任务)可以经历的潜在状态转换。
请参阅: 任务、重试和流程的状态 以获取更多详细信息。
通知
也称为: 你如何获得有关状态转换、任务结果、任务进度、作业发布等的通知...
请参阅: notifications 以获取更多详细信息。
回滚 (Reversion)
tasks 和 flows 都可以通过执行任务对象上的相关回滚代码来回滚。
例如,如果 flow 请求带有附加块存储的服务器,通过组合两个任务
task1: create server || rollback by delete server task2: create+attach volume || rollback by delete volume
如果附加卷代码失败,流程中的所有任务都将使用其回滚代码回滚,从而删除服务器和卷。
持久化 (Persistence)
TaskFlow 可以将当前 atom 状态、进度、参数和结果以及流程、作业等保存到数据库(或其他任何位置),从而实现 flow 和 atom 恢复、检查点和回滚。Taskflow 提供了一个持久化 API 以及基本的持久化类型,用于确保作业、流程及其关联的原子可以备份到数据库或内存中(或其他位置)。
参见: 持久性,了解为什么需要持久性以及如何使用它。
检查点
一个正在进行中的主题/讨论是检查点概念。
参见: 检查点
恢复
如果一个 flow 启动,但在完成之前被中断(例如,控制进程被杀死),则该 flow 可以在其最后一个检查点安全地恢复。 这允许服务进行安全且简单的崩溃恢复。 TaskFlow 为检查点日志提供不同的持久性策略,让您作为应用程序开发人员选择适合应用程序的使用和所需功能的策略。
输入和输出
参见: 输入和输出,了解 flow、atom 和 engine 产生/消耗/发出的各种输入/输出/通知的更多详细信息。
范式转变
参见: 范式转变,以查看使用(或在使用后)taskflow 可能导致的一些变化。
最佳实践
参见: 最佳实践,获取在使用 taskflow 时常见的有用的最佳用法和最佳实践。
架构
参见: 架构,获取使用/开发 taskflow 的一些*实际*架构。
过去、现在和未来
过去
TaskFlow 最初是与 NTTdata 公司和 Yahoo! 合作为 Nova 开发的原型,现在已发展成为更通用的解决方案/库,可以形成多个 OpenStack 项目的基础结构。
考古学
参见: NovaOrchestration(2011 年秋季)
参见: StructuredStateManagement(2013 年春季)
参见: StructuredWorkflows(2013 年春季)
参见: StructuredWorkflowPrimitives(2013 年春季)
参见: DistributedTaskManagement(celery 互操作尝试,2013 年)
现在
目前: 我们目前正在收集需求,并继续进行 taskflow(库)的工作,以及与各个项目的集成。
积极集成
未来
计划/期望/可能的...集成
计划开发
请在贡献之前阅读 蓝图。
示例
请前往 这里
核心贡献者(过去和现在)
- 刘昌斌 (AT&T Labs)
- Doug Hellmann (HP)
- Davanum Srinivas (Mirantis)
- Anastasia Karpinska (Grid Dynamics)
- Min Pae (HP)
- Ivan Melnikov (Grid Dynamics)
- Daniel Krause (Rackspace)
- Greg Hill (Rackspace)
- Jessica Lucci (Rackspace)
- Joshua Harlow (Yahoo!)
- Rohit Karajgi (NTT Data)
- Pranesh Pandurangan (Yahoo!)
- 你!!
会议
加入我们!
Launchpad: http://launchpad.net/taskflow
核心: 团队
审查: 帮助 代码审查
联系我们!
IRC: 您也可以在 OFTC 的 #openstack-state-management 中找到我们
邮件列表: openstack-dev(在主题前加上 [TaskFlow] 以获得更及时的回复)
博客/教程/视频/幻灯片
- http://www.dankrause.net/2014/08/23/intro-to-taskflow.html
- http://www.giantflyingsaucer.com/blog/?p=4896
- http://github.com/sputnik13/tutorials_and_quickstarts/tree/master/taskflow
- https://docs.google.com/presentation/d/1EZoY4FE2SDjfCqMCgBRrwo7ovHF4vYZFGKjjvFvWHIE/
- http://www.slideshare.net/harlowja/taskflow-27820295
- https://docs.google.com/presentation/d/14r92RXQLXYcJwygWM4OsfeUyvNHtZAYl572G9DFwigo/