NovaOrchestration
| |
旧设计页面
此页面曾用于帮助设计 OpenStack 的先前版本中的一项功能。该功能可能已经或尚未实现。因此,此页面可能不会更新,并且可能包含过时的信息。上次更新时间为 2014-11-02 |
NovaOrchestrationBrainStorming
Nova 中的长期运行事务
这是一个正在进行中的工作
什么是长期运行事务?长期运行事务是一种业务活动,其步骤之间可能需要等待很长时间。例如,如果您是公司的新员工,人力资源部门可能需要在您开始工作的第一天之前执行以下操作:
- 为您分配一个停车位
- 为您办理门禁卡
- 将您添加到人力资源系统
- 为您办理医疗保健和福利
- 为您找到桌子、椅子等
- 确定您将向谁汇报
- 为您订购一台电脑
- 等等。
从开始到每个任务的结束可能需要很长时间。每个任务本身可能由许多其他长期运行事务组成。此外,其中许多任务可以并行执行,这意味着我们必须能够分叉许多子事务并在继续之前在某个时刻将它们连接在一起。
在流程开始和结束之间,可能会发生大量的 IT 事件。服务器可能会崩溃,添加新服务器,数据库更改,电源故障等。我们不能假设传统的“流程”足以处理这些长期运行的操作。
Nova 有许多需要管理的长期运行事务。最重要的是实例的配置。考虑一个配置 1000 个实例的请求。我们必须执行以下步骤:
- 与所有区域通信,并为该请求制定构建计划。
- 将“配置”操作委托给每个区域中的每个主机以创建实例。
- 等待所有主机的配置完成。
- 如果请求失败,则在另一个主机上重试该请求(来自构建计划)
- 定期创建一个新的构建计划,其中包含更新的数据。
- 如果所有这些花费的时间太长,我们可能需要取消事务,并通知请求者。
从操作开始到失败(或完成),启动请求的调度器可能已经死亡并重新启动了十几次。我们需要能够将此事务作为外部观察者进行监视,并在一段时间内“编排”该事务。
解决方案关注点
主要问题是确定事务步骤(也称为“工作项”)的成功/失败。幸运的是,Nova 集成了通知系统。工作项成功和失败事件会通过 Rabbit 队列在成功和失败时发送。为了审计/计费目的,当实例启动或停止时会发送通知。同样,当发生错误时(目前仅在 Compute 节点中),会发送通知到“error”队列。
像 Yagi 这样的框架可用于收集这些事件并将它们可靠地中继到其他系统进行处理。例如,可以将这些事件发送到 PubSubHubBub 服务器,以中继给感兴趣的消费者。
此外,对于任何将对服务器故障具有弹性的解决方案,该解决方案需要基于某种状态机,其中状态持久保存在数据库中。仅仅在服务中运行一个“监视线程”是不够的。当仅管理单个状态时,简单的状态机就足够了。交通灯是一个单状态机。它要么是红色、黄色或绿色。对于更复杂的系统,特别是涉及并发的情况,许多状态机可能需要交互。
例如,考虑最初配置 100 台服务器的情况。这可以在并行完成。我们可以发出 100 个请求并监视每个请求,以查看实例、磁盘和网络是否都已正确设置。本质上,我们正在启动 100 个小状态机,然后有一个主状态机监督每个子任务。现在,我们可以使用嵌套的单状态机来实现这一点,但还有其他数据结构更适合解决这个问题。
成功解决方案的关键是保证状态机中的转换是幂等的,同时允许水平可扩展的解决方案。换句话说,我们需要能够启动多个编排服务器,但任何一个服务器都必须确保其执行的操作不会被其他编排服务器重复。或者,如果重复了,净效果相同。因此,我们将解释为什么基于 Yagi 的解决方案不是最佳方法,以及替代方案。
提案
该提案基于许多不同的讨论,这些讨论以非正式或在邮件列表中进行,是拥有一个新的“编排”服务来管理这些长期运行事务。当 Nova 中启动一个可能需要一段时间才能运行的新活动时(例如启动/停止大量服务器),将在编排服务中启动一个新的工作流流程。
该服务通过其相关的 API 与每个 nova 服务进行通信,以启动工作。然后它直接从成功/失败通知队列监听来自这些操作的成功/失败。
随着流程的继续,每个步骤可能由其他编排服务器处理……不一定是启动流程的服务器。
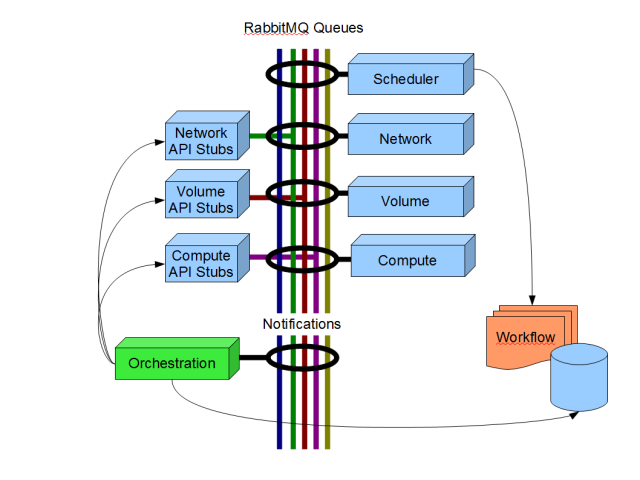
为什么不使用 Yagi? 因为当我们与 yagi-feed 通信时,我们会提供上次通话时间的 etag。这本质上是说“给我自 X 以来发生的所有事件”。我们将获得一连串事件,编排服务器需要逐一处理它们。如果编排服务器死亡,它将在下一次轮询时重新处理相同的事件(没有每个消息的 etag,只有每个请求的 etag……从技术上讲,我们只能请求一个事件,但这似乎效率低下)。此外,如果我们水平扩展编排服务器,则无法保证两个服务器会同时获取相同的 feed。
相反,让我们让 rabbit 做它最擅长的事情……确保队列中事件的原子处理。
但是,我们需要更改一些事情。目前,我们的 rabbit 处理在从队列中提取消息时会立即 ACK 消息。如果服务在处理消息时死亡,则消息将丢失。相反,对于编排服务,我们希望在处理完事件后才 ACK 事件。(虽然,同样值得商榷,如果服务在处理事件后但在 ACK 消息之前死亡,仍然存在可能多次处理同一事件的窗口)。我们仍然需要防止状态机中重复处理。
注意: 我不知道编排是否需要成为一个独立的服務,或者是否可以属于现有的调度器(已经负责路由)……这似乎很可能。
第一步
此实现的第一步是将构建计划从调度器传递到编排服务以供执行。可以扩展此存根,供希望使用自己的工作流解决方案的客户使用。
第二步
绑定一个精益高效的工作流解决方案来处理状态机管理。这应该是一个基于 Petri 网的状态机,以便它正确支持并发工作流。也许像 Spiff Workflow 这样的纯 Python 基于的解决方案,没有 DB 或 UI 层或其他杂物。
或者,也许可以使用一个简单的单状态机来启动事情?
第三步
模拟一些基本的工作流,看看它们在负载下的工作方式。然后迭代、迭代、迭代。添加更多工作流。从 Nova 核心中删除越来越多的硬编码业务逻辑,并将其放入被认为最好的语法中。添加更多用于失败/成功条件的陷阱。专注于生成事件,而不是实例特定的重试/错误处理代码。
快速失败与自动化
我听到的一种对此提案的担忧是重试很困难。我们如何知道重试不会对正在失败的主机造成更多损害?这可能是可能的,但重试同一服务器(或者根本不重试)不是强制性的。
将此硬编码重试逻辑(例如)移动到编排的原理是,其他组可以管理成功/失败条件发生的工作流。
自动化这些流程应该是任何运行 Openstack 的人的首要任务。操作员需要执行的手动检查、更正和调整越多,他们的效率就越低。我们希望将所有这些业务逻辑外部化到一个地方,
- 易于更改
- 易于理解
将复杂的重试/通知/错误处理业务逻辑嵌套在 Python 代码中似乎不是运行操作中心的高效方式。目前 nova 是快速失败的。如果出现问题,操作将结束,我们将在日志中查找发生了什么。抽象级别需要稍微提高一点,以便可以进行流程自动化。请注意,不要将此与系统操作监控混淆,例如负载监控、磁盘监控、网络监控等,这些都由其他系统控制。
附录
调度器改进与独立服务
1) 调度器可以快速失败,编排器可以重试
- 添加失败原因 - 例如,计算节点无法分配资源与灾难性故障,原因可能无法确定。
- 重试逻辑可配置
2) 编排器重试逻辑示例
- 定义 MAX_RETRY_COUNT、MAX_SAME_HOST_RETRY_COUNT(< MAX_RETRY_COUNT)
- 如果资源分配失败(直到 MAX_RETRY_COUNT),则重试另一个主机 - 在发生灾难性故障的情况下,重试同一主机直到 MAX_SAME_HOST_RETRY_COUNT - 否则尝试另一个主机(直到 MAX_RETRY_COUNT)
3) 更容易地服务允许的区域内请求
- 通过将编排逻辑从调度器中移开,区域内请求可能由多个编排器处理。使用调度器+实现,这将很复杂。
基于 Rabbit-MQ 的实现
提出的问题
- 在处理请求时流程死亡或请求被处理多次时会丢失 ACK。
提出的缓解措施
- 对于每个请求,我们可以将 处理 状态推回队列,并在处理后 ACK 吗?
- 如果请求处于处理中,但没有 ACK,编排器将知道有人正在处理它。这是为了防止请求被处理两次。
- 我们还可以为每个请求添加 重试后 和 超时 (超时 > 重试后)。即使请求处于处理状态或未收到 ACK,重试后也是编排器尝试重新处理请求的时间。这是为了确保请求不会被遗漏。
- 超时是编排器放弃的时间。这是为了防止争用
后续步骤
- 为提议的 3 个步骤添加更多细节
- 为状态机添加更多细节
附加页面
<<PageList(NovaOrchestration/)>>