Sahara/NextGenArchitecture
目前 Sahara 是一个在单个 Python 进程中运行的单一服务。所有的 REST API、数据库交互、配置机制都在一起工作。这在集群创建时产生很多高 I/O 负载的问题,以及缺乏高可用性等。
应该有两个阶段来改进 Sahara 架构。
目录
阶段 1:将 Sahara 分解为不同的服务
Sahara 应该被分解为两个可水平扩展的服务
- sahara-api (s-api);
- sahara-engine (s-engine)。
此外,数据库访问层应该从主代码中解耦为 'conductor' 模块
在这个阶段,应该解决以下问题
- 解耦 UI 和配置
- 即使配置部分完全繁忙,UI 也应该具有响应性;
- 启动大型集群
- 需要使用多个引擎来配置一个 Hadoop 集群;
- 将集群创建分解为许多原子任务;
- 非常重要的是支持从多个引擎并行 ssh 到许多节点;
- 一次启动多个集群
- 需要利用多个进程;
- 需要利用多个节点;
- 长期运行的任务
- 我们应该避免在一个引擎上等待很长时间,以最大限度地降低中断风险;
- 新的配置插件 SPI
- 它应该使插件的配置更容易;
- 它应该生成可以同时执行的任务;
- 支持 EDP
- 它需要长期运行的任务;
- Sahara 应该支持同时运行多个任务(一个集群上的多个作业);
- 还有其他?
接下来的几个部分解释了建议的 Sahara 服务含义和职责。
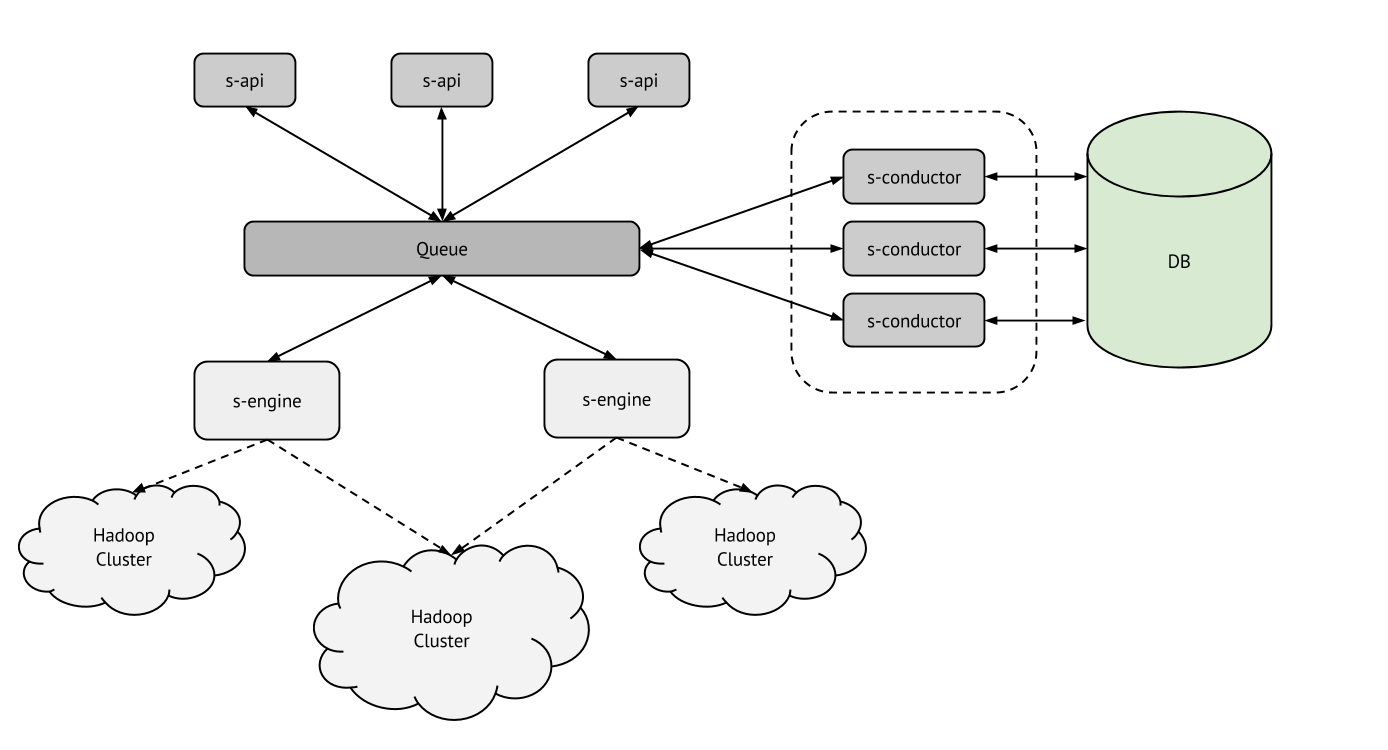
服务 sahara-api (s-api)
它应该是可水平扩展的,并使用 RPC 来运行任务。
职责
- REST API
- http 端点/方法验证;
- 对象存在性验证;
- 基于 jsonschema 的验证;
- 插件或操作特定的验证
- sahara 侧验证(例如,应该限制删除在其他模板或集群中使用的模板);
- 要求插件验证操作;
- 为操作创建初始任务;
- 该服务将是 Sahara 的端点,应该在 Keystone 中注册,如果有很多 sahara-api,我们应该使用 HAProxy 作为端点,它将在多个 sahara-api 之间平衡负载;
- 与 OpenStack 组件交互
- 使用 Keystone 进行身份验证(未来我们需要采用 trust 或其他机制来支持长期运行的任务和自动扩展);
- 使用 Nova、Glance、Cinder、Swift 等进行验证。
服务 sahara-engine (s-engine)
Sahara engine 服务应该执行任务并创建新的任务。它可以调用插件来完成某些操作。职责
- 运行任务和长期运行的任务;
- 与其它 OpenStack 组件交互
- 使用 Nova、Glance、Cinder 创建不同的资源(实例、卷、IP 等)。
任务执行框架
我们应该创建任务执行框架的草案并实现它,以利用可水平扩展架构的优势。
用于讨论和起草它的 Etherpad:https://etherpad.openstack.org/savanna_tasks_framework
Conductor 模块
该模块应该负责与数据库交互并隐藏数据库,使其不被其他组件访问。
职责
- 数据库交互;
- 不与其它 Sahara 和 OpenStack 组件交互。
阶段 2:为配置任务实现高可用性
Sahara 中的所有重要操作都应该是可靠的,这意味着 Sahara 应该支持回放事务和回滚所有任务。这里有一个用于执行此操作的库 https://wiki.openstack.org/wiki/TaskFlow 在 stackforge 中。看起来它可以在 Sahara 架构改进的第二阶段中使用。为了解决可靠性和一致性问题,我们可能应该添加一个用于任务/工作流协调的 Sahara 服务 - sahara-taskmanager (s-taskmanager),它也应该是可水平扩展的。
在这个阶段,应该解决以下问题
- 对工作流的支持;
- 任务/工作流执行的可靠性;
- 长期运行任务的可靠性。
主要操作执行流程
通用流程提示
- DB 对象将仅在负责 DB 交互的模块 ('savanna/db/sqlalchemy') 中使用;
- 所有与数据库相关的类的导入都应该位于此模块 ('savanna/db/sqlalchemy') 中;
- 在 sahara-api 和 sahara-engine 中,我们将使用简单的资源对象(实际上是字典);
- 待定 (TBD)。
创建模板
- [s-api] 解析传入请求;
- [s-api] 执行模式和基本验证;
- [s-api:plugin] 执行模板的高级验证;
- [s-api:conductor] 将模板存储在数据库中;
- [s-api] 向用户返回响应。
启动集群
- [s-api] 解析传入请求;
- [s-api] 执行模式和基本验证;
- [s-api:plugin] 执行集群创建的高级验证;
- [s-api:conductor] 将集群对象存储在数据库中;
- [s-api] 向用户返回响应;
- [s-api] 调用 sahara-engine 启动集群;
- [消息队列 / 本地模式];
- [s-engine-1] 开始准备集群的基础设施;
- [s-engine-1:plugin] 更新集群的基础设施需求(例如,添加管理节点,更新实例的一些属性,设置初始脚本等);
- [s-engine-1] 启动任务以创建所有基础设施并等待其完成;
- [消息队列 / 本地模式];
- [s-engine-2 | s-engine-3 | s-engine-X] 从 MQ 运行任务,它可以创建实例并在其上运行命令,创建和附加 cinder 卷等;
- [s-engine-1] 所有基础设施准备就绪,继续;
- [s-engine-1:plugin] 通过为集群节点创建文件和脚本的任务来配置集群;
- [消息队列 / 本地模式];
- [s-engine-2 | s-engine-3 | s-engine-X] 从 MQ 运行任务,它可以上传文件、运行脚本等;
- [s-engine-1:plugin] 启动任务以启动节点上所需的服务(集群启动);
- [s-engine-2 | s-engine-3 | s-engine-X] 从 MQ 运行任务,它可以运行某些服务;
- [s-engine-1:conductor] 更新集群状态;
扩展集群
与“启动集群”操作的行为相同。
附加说明
一体化安装
我们希望使 "savanna-all" 二进制文件支持一体化 Savanna 执行,用于小型 OpenStack 集群和开发/质量保证需求。
一些说明和常见问题解答
为什么不将配置代理部署到 Hadoop 集群以配置所有其他内容?
这种行为存在几个缺点
- 在启动大型集群时,代理的扩展将存在问题;
- 在集群扩展期间,我们可能会遇到代理迁移问题;
- 代理是意外的实例资源消耗者(这可能会影响 Hadoop 配置);
- 这些代理需要与所有其他服务通信(相同的消息队列,相同的数据库等),用户将能够登录到这些实例,因此这是一个安全漏洞;
- 我们需要支持各种 Linux 发行版,以及不同的 python 和 lib 版本。
为什么现在不实现高可用性?
我们目前的主要重点是实现 EDP 并通过支持使用多个引擎来配置一个 Hadoop 集群和同时配置多个 Hadoop 集群来提高 Sahara 的性能。因此,我们希望将这项艰巨的工作分解为几个步骤并逐步进行。
为什么我们需要长期运行的操作?
有一些我们需要执行的长期运行的操作,例如,在减少集群大小时进行退役。
服务之间如何交互?
Oslo RPC 框架和消息队列(RabbitMQ、Qpid 等)将用于服务之间的交互。
确定架构升级成功的潜在指标
- s-api
- 每秒处理的请求数(每个请求组);
- s-engine
- 每个 Sahara 控制器同时启动的 Hadoop 集群数;
- 在特定数量的控制器上使用特定数量的节点创建单个 Hadoop 集群的速度;
- 具有特定数量节点的集群创建时间(不包括实例启动时间)。