Sahara/Templates
Hadoop 拥有大量的参数,终端用户很难找到合适的配置来使集群达到良好的性能。模板机制简化了 Hadoop 集群的创建和配置过程。终端用户只需要指定集群模板并提供需要更改的参数。集群配置将来自模板。假设模板是由经验丰富的 Hadoop 管理员创建的。如果用户需要重新定义一个参数,他可以创建一个自定义模板或在集群创建期间覆盖该参数。
模板的使用受到两件事的限制:插件和 Hadoop 版本。模板始终是插件特定的,因为它包含特定于插件的配置。这意味着只能将模板与创建它的插件一起使用。同样适用于 Hadoop 版本。
Sahara 有两种类型的模板:集群模板和节点组模板。
节点组模板
节点组模板包含集群中一个节点的配置。它的名称中带有“节点组”,是因为集群由具有相同配置的节点组组成。模板包括 Hadoop 进程和 VM 特性(例如,任务跟踪器的 reduce slots 数量、CPU 数量和 RAM 容量)的配置。VM 特性使用 OpenStack flavor 指定。
节点模板包含以下参数
| 姓名 | 类型 | 约束 | 评论 |
|---|---|---|---|
| id | 字符串 | 必需,唯一 | |
| flavor | 字符串 | 必需,应包含有效的 flavor id | |
| name | 字符串 | 必需,唯一 | |
| description | 字符串 | 可选 | |
| plugin | 字符串 | 必需,应包含有效的 plugin id | |
| hadoop_version | 字符串 | 必需 | |
| node_processes | 字符串列表 | 必需 | |
| node_configs | 字典的字典 | 必需 | 有关确切结构,请参见下面的示例 |
示例
{
"id": "aee4-strf-o14s-fd34",
"flavor": "4",
"image": "ah91-aij1-u78x-iunm",
"name": ”fat task tracker + data node”
"description": “a template for big nodes ...”,
"plugin": “apache-hadoop”,
"hadoop_version": “1.1.1”
"node_processes": [“task tracker”, “data node”]
"node_configs":
{
”service:mapreduce”:
{
"mapred.tasktracker.map.tasks.maximum": 8,
"mapred.tasktracker.reduce.tasks.maximum": 3,
...
}
”service:hdfs”:
{
…
}
”general”:
{
…
}
}
}
集群模板
集群模板包含应用于整个集群的配置,例如 HDFS 复制因子或 HDFS 块大小。它还包含节点组模板列表。理想情况下,这将允许用户通过仅指定集群模板,一键创建集群。
| 姓名 | 类型 | 约束 | 评论 |
|---|---|---|---|
| id | 字符串 | 必需,唯一 | |
| name | 字符串 | 必需,唯一 | |
| description | 字符串 | 可选 | |
| plugin | 字符串 | 必需 | |
| hadoop_version | 字符串 | 必需 | |
| configs | 字典 | 必需 | |
| node_groups | 字典列表 | 必需 | 有关确切结构,请参见下面的示例 |
示例
{
"id": "asdf-wdvc-9as0-q23w",
"name": ”small cluster”,
"description": “a template for a small cluster”,
"plugin": “apache hadoop”,
"hadoop_version": “1.1.1”
"configs":
{
"service:mapreduce":
{
"compression": "snappy"
}
"service:hdfs":
{
"hdfs_replication_factor": 3
}
"general":
{
...
}
}
"node_groups_templates":
[
{
"name": "master node",
"node-group-template": "aee4-strf-o14s-fd34",
"count": 1
},
{
"name": "workers",
"node-group-template": "fe1t-2t4f-1oa4-fdik",
"count": 3
}
]
}
插件集成
插件应提供以下功能以支持模板
- 通过实现 get_configs(...) 方法提供配置列表
- 在 validate_cluster(...) 方法中,插件必须验证用户为 configs 指定的输入。
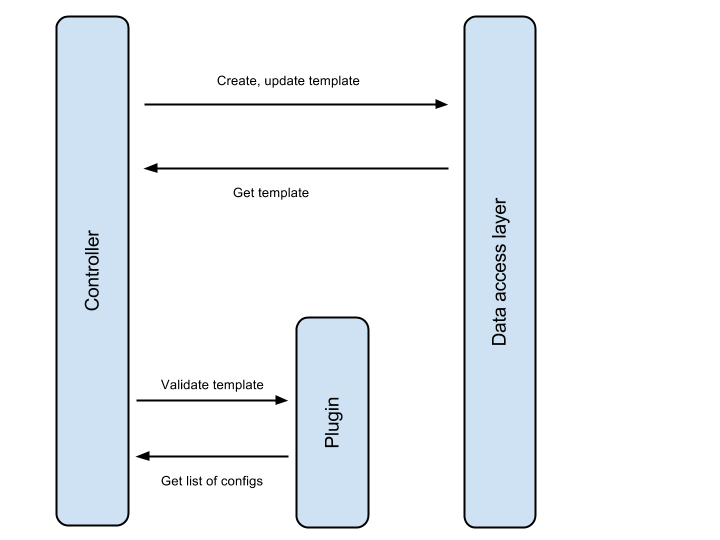
Configs
插件应提供用户可编辑的配置列表。本质上,“config”是单个参数的规范。该参数可以针对通用配置或特定服务(mapreduce、hdfs)配置。它也可以具有集群或特定节点组的范围。范围决定了配置将出现在哪种类型的模板中。范围为“cluster”的配置将出现在集群模板中。
范围为“node”的配置同时出现在集群模板和节点组模板中。当它们在集群模板中指定时,它们将作为节点模板中使用的默认值的新的默认值。
由于插件提供配置列表,因此它还必须能够在用户提供一些值时将它们应用于集群。
示例配置
{
"name": “mapred.tasktracker.map.tasks.maximum”,
"applicable_target": ”service:mapreduce”,
"scope": "node"
"default": 2,
"required": true,
"type": “int”,
"description": “amount of map tasks per node”
}