RabbitmqHA
- Launchpad 条目: NovaSpec:rabbitmq-ha
- 创建时间: 2010年10月19日
- 上次更新: 2010年10月19日
- 贡献者: Armando Migliaccio
总结
本文档描述了 Nova 如何支持 RabbitMQ 配置,例如集群和主动/被动复制。
发布说明
Nova RPC 映射的 Austin 版本仅处理间歇性网络连接问题。为了支持 RabbitMQ 集群和主动/被动代理,需要提供更高级的 Nova RPC 映射,例如处理集群内持有队列的节点故障以及主动/被动复制的主/从故障转移的策略。
原理
目前,消息队列配置变量与 nova/flags.py 中的 RabbitMQ 绑定。特别是,仅提供一个 rabbitmq 主机,并且为了简化部署,假定单个实例正在运行。如果 RabbitMQ 主机发生故障(例如,磁盘或电源相关),Nova 组件将无法从队列系统中发送/接收消息,直到其恢复。为了提供更高的弹性,可以将 RabbitMQ 配置为主动/被动设置,以便在主动节点发生故障时,能够从被动节点恢复已写入磁盘的持久消息。如果需要高可用性,可以使用共享磁盘存储、心跳/pacemaker,以及服务副本前方的 TCP 负载均衡器来实现主动/被动 HA。虽然此解决方案确保了更高程度的客户端透明度(例如,Nova API、Scheduler 和 Compute),但它仍然是整体架构的瓶颈,可能需要昂贵的硬件来运行,因此远非理想。
另一种选择是 RabbitMQ 集群。RabbitMQ 集群(或代理)是多个 Erlang 节点的一个逻辑分组,每个节点运行 RabbitMQ 应用程序并共享用户、虚拟主机、队列、交换器、绑定等。在虚拟设备的环境下,采用 RabbitMQ 集群变得很有吸引力,其中每个设备专用于单个特定的 Nova 任务(例如,compute、volume、network、scheduler、api,...),并且它也运行一个 RabbitMQ 服务器实例。通过将所有实例集群在一起,将提供一个跨部署的单个大型集群,从而提供以下好处
- 没有单点故障
- 不需要昂贵的硬件
- 不需要单独的设备/主机来运行 RabbitMQ
- RabbitMQ 在部署中变得“隐藏”
然而,有一个问题可能会阻碍这种场景的实现:所有数据/状态(用于 RabbitMQ 代理的操作)都在所有节点之间复制;消息队列是例外,目前,它们仅驻留在创建它们的节点上。队列仍然可以从所有节点看到和访问,但在持有它们的节点发生故障时,会发生坏事! 这也是为什么集群不鼓励用于高可用性,并且主要用于提高可扩展性。 尽管如此,如果相应地实施客户端故障转移策略,它们的选择仍然很有吸引力。
为了理解为什么当前的 Nova RPC 映射不能使用 RabbitMQ 集群,以及节点崩溃如何导致灾难性故障,请继续阅读。
用户故事
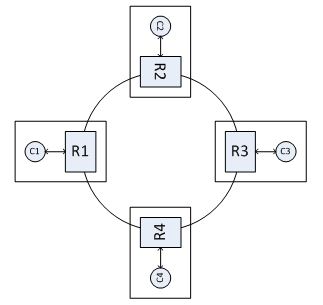
Nova 使用基于主题的队列,这些队列在相同类型的组件之间共享(例如,“compute”或“scheduler”)。当使用集群时,队列仅在单个节点上创建,并且该节点成为首次声明队列的节点。 任何后续尝试重新声明队列都是无操作的。 现在,考虑下图所示的集群配置:R1、R2、R3 和 R4 是 RabbitMQ 代理的一部分,并且每个客户端 Ci 通过本地实例 Ri 连接到代理。 让我们也假设 C1 是一个 API 组件,C2、C3、C4 是 Scheduler 组件;最后,假设共享队列是在 RabbitMQ 节点 R2 上创建的。 在这种集群配置和当前的 Nova 代码库中,C3 和 C4 仍然会通过在 C2 上创建的队列连接。 然而,R2 的故障是灾难性的:C1 发布的消息将被丢弃(发布者可能会看到他们的消息从队列系统中丢弃,因为 AMQP 允许没有路由的消息),并且 C3 和 C4 将不会检测到任何故障。 此外,如果队列是持久的,C3 或 C4 无法在另一个节点上重新创建它们,因为 RabbitMQ 实现禁止这样做。
前提条件
待定
设计
待定
实现
待定
代码变更
待定