多集群区域
| |
旧设计页面
此页面曾用于帮助设计 OpenStack 之前版本的一个特性。它可能已经实现,也可能没有实现。因此,此页面可能不会更新,并且可能包含过时的信息。上次更新时间为 2014-03-22 |
- Launchpad 条目: NovaSpec:multi-cluster-in-a-region
- 创建:
- 贡献者: SandyWalsh
总结
区域是 Nova 服务和 VM 主机的逻辑分组。并非所有区域都需要包含主机;它们也可以包含其他区域,以允许更易于管理的组织结构。我们对区域的设想也允许存在多个根节点(顶级区域),以便业务部门可以以不同的方式对主机进行分区,用于不同的目的(例如,地理区域与功能区域)。
本提案将概述我们对多集群问题理解,并讨论一些实现想法。
讨论
请将所有反馈/讨论发送到邮件列表或以下 Etherpad: http://etherpad.openstack.org/multiclusterdiscussion
我将维护此页面以反映反馈。 -SandyWalsh
参见
旧的笔记: http://etherpad.openstack.org/multicluster 和 http://etherpad.openstack.org/multicluster2
发布说明
todo
原理
为了将 Nova 扩展到 100 万台主机和 6000 万个客户实例,我们需要一种分而治之的方案。
前提条件
设计
让我们看看 Nova 目前是如何组合在一起的。
有一组 Nova 服务通过 AMQP(当前为 RabbitMQ)相互通信。每个服务都有自己的队列用于发送消息。为了方便起见,还有一组服务 API 存根,用于处理将命令编组到这些队列中。每个服务都有一个服务 API。外部工作通过其中一个面向公众的 API(当前为 EC2 和 Rackspace/OpenStack over HTTP)与 Nova 通信。在客户端可以与面向公众的 API 通信之前,它必须对 Nova Auth 服务进行身份验证。身份验证后,Auth 服务将告诉客户端使用哪个 API 服务。这意味着我们可以启动许多 API 服务并将调用者委托给最合适的 API 服务。API 服务对请求进行很少的处理。相反,它使用服务存根将消息放到适当的队列上,相关的服务处理请求。
当前大约有半打 Nova 服务在使用。这些包括
- API 服务 - 如上所述
- 调度器服务 - 来自 API 的事件的第一个站点。调度器服务负责将请求路由到适当的服务。当前实现没有做太多。此服务可能会受到此提案的影响最大。
- 网络服务 - 用于处理 Nova 网络问题。
- 卷服务 - 用于处理 Nova 磁盘卷问题。
- 计算服务 - 用于与底层虚拟机管理程序通信并控制客户实例。
然后还有其他服务,如 Glance、Swift 等。
下图显示了此流程。请注意,我展示了底部建议的通知方案,但当前 Nova 中没有此方案。
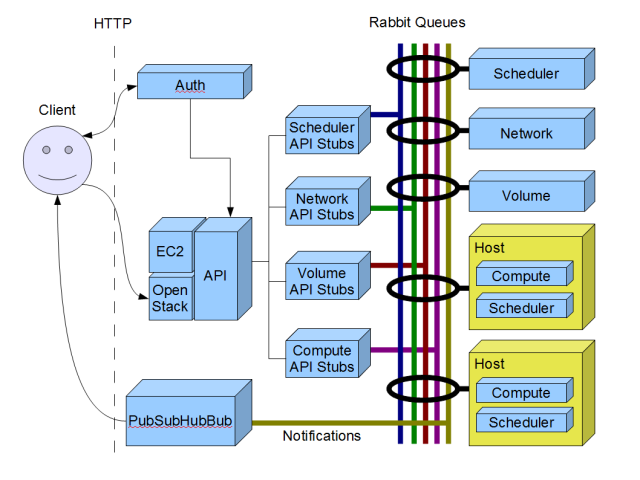
这种架构对于我们现有的部署来说很好。但是,随着我们扩展,它的性能会下降,直到变得无法使用。同样,它也可能由于硬限制而失败,例如子网中可用的网络设备的数量。我们需要找到一种分区主机的方法,以便能够进行更大的部署。
一种方法是支持“区域”。
区域是 Nova 服务的逻辑分组。区域可以包含其他区域(因此是本提案的嵌套方面)。与传统的树状结构不同,区域可以有多个根节点。如果我们只允许单个根节点,则可能只能使用一种组织方案。但是,不同的业务部门可能需要从不同的角度查看主机集合。运营可能希望根据功能查看主机,但最终用户、销售或营销可能希望按地理位置组织它们。地理位置是最常见的组织方案。
在每个区域内,我们可以启动 Nova 服务的一个集合/子集,并在区域之间委托命令。区域将通过 AMQP 网络相互通信。
一个示例嵌套区域部署可能如下所示
(A = API 服务,S = 调度器服务,N = 网络服务,V = 卷服务,等等)
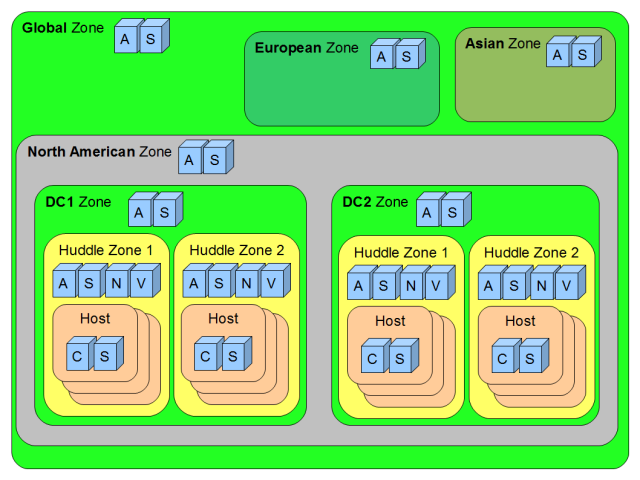
如您所见,有一个名为“Global”的顶级区域。Global 区域包含北美、欧洲和亚洲区域。深入到北美区域,我们看到两个数据中心 (DC) 区域 #1 和 #2。每个 DC 都有两个 Huddle 区域(借用 Rackspace 的术语),实际主机服务器位于其中。由于网络限制,Huddle 区域的大小限制为 200 台主机。
最大的区域肯定是 DC 区域,其中包含大量 Huddle 区域。在服务提供商部署中,我们可以假设一个 DC 区域可能包含 200 个或更多 Huddle 区域。假设每台主机大约有 50-60 个客户实例,单个 DC 可能负责多达 200 个 Huddle 区域/DC * 200 台主机/HuddleZone * ~50 个客户/主机 = ~200 万个客户/DC。
我们的意图是在最后时刻才将主机与区域的决策责任分开,从而使工作集尽可能小。
区域间通信和路由
如前所述,AMQP 用于服务之间的通信。此外,我们还提到调度器服务用于在服务之间路由请求。多集群的策略是让调度器服务在将请求交给最终目的地之前,在区域之间路由调用。
最初的设想是每个区域都有自己的 AMQP 队列用于接收消息。每个区域将部署一个调度器,可以侦听来自父区域的请求。这意味着我们需要配置 AMQP 网络,以便只有区域间队列在 AMQP 集群中复制,而不是网络中的每个队列。
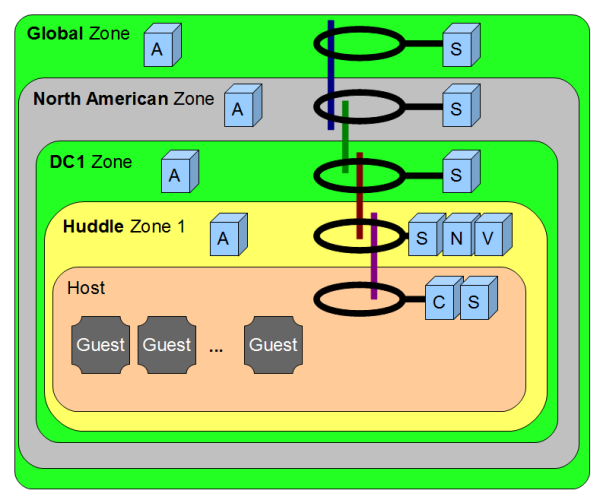
事实证明,这并不是一个可行的方案。配置 RabbitMQ 以跨越 WAN 确实有效,我们在 DFW/ORD 测试中获得的数据也不错。但是,我们在 WAN 设置中遇到了一些奇怪的问题,这些问题只出现在 WAN 设置中。此外,RabbitMQ 不支持使用称为 Shovel 的另一个工具进行集群间通信。虽然 Shovel 似乎被用于大型生产环境中,但该项目的开发工作似乎很轻,完全依赖它可能存在风险。各种因素表明,我们可能还需要考虑通过我们现有的 API 进行区域间通信。
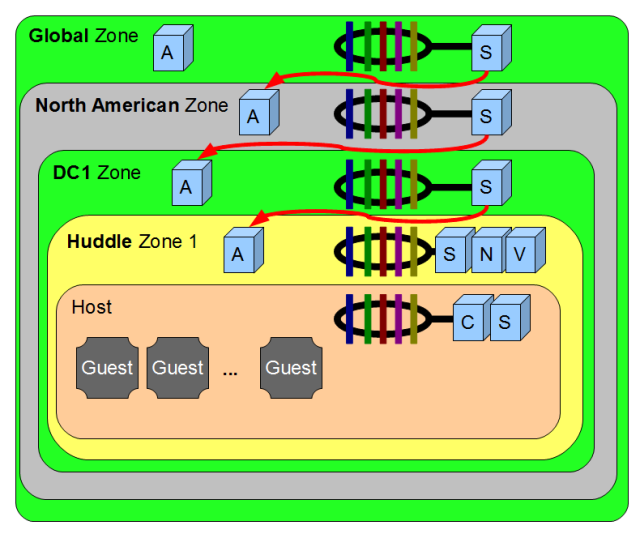
虽然有点笨拙,但我们可以获得区域之间的良好隔离。
我的建议是放置适当的抽象,以便我们可以使用这两种方法,并首先关注公共 API 方法。希望,将来有人有更多时间来深入研究 Shovel 路线。
我们应该使用队列还是公共 API?
这种方法的优点和缺点是什么?
使用 AMQP 进行区域间通信
优点
- AMQP 专为此目的而设计。
- 所需的编组较少,这意味着代码较少。
- 轻松支持回调。
- 更易于 Nova 管理员设置。
缺点
- 需要 WAN RabbitMQ 集群。
- RabbitMQ 需要 Shovel 进行集群间通信。
- 在 Celery 测试期间出现了一些奇怪的错误条件。
- 构建一个非常单体化的结构(中央数据库),这增加了我们对单个故障点的依赖。
使用公共 API 进行区域间通信
优点
- 更轻松的部署
- 开发人员更容易理解通信。
- 发生故障时,区域之间的良好隔离。
缺点
- 呼叫者身份验证必须存储并转发到每个 API 服务进行每个调用。
- 没有用于长运行操作的回调或错误通知的手段,除非是建议的
[[PubSubHubBub]]服务。 - 将每个请求从 HTTP -> Rabbit -> HTTP -> Rabbit 一直编组/解组的费用。
- 必须注册公共 API,以及每一层上的仅管理员 API。我们需要检测调用是否为仅管理员调用,并正确路由到适当的 API 服务器。
路由、数据库实例、区域、主机和功能
Nova 区域的每个部署都具有完整的 Nova 应用程序套件副本。每个部署也都有自己的数据库。所有部署在所有级别上的数据库模式相同。部署之间的区别在于,根据在该区域中运行的服务,并非所有数据库表都会被使用。
我们需要在 Nova DB 中添加一个区域表,其中包含所有子区域。父区域将向下查询到其子区域以获取功能、区域名称和当前状态。子区域不知道其父区域。这将允许使用多个父区域和不同的区域层次结构。
主机不必只位于叶节点。主机可以位于任何级别。主机包含在区域内。我认为,但不确定,它们也可能属于多个区域树。我需要对此进行扩展。
如前所述,区域和主机具有功能。功能是键值对,指示区域或主机中包含的资源类型。功能用于决定将请求路由到哪里。
功能键值对的 value 部分是一个 (String/Float, Type) 元组。Type 字段用于强制转换两个值字段 (string/float)。我们有一个 String 和 Float 字段,因此我们可以在数据库中进行范围比较。虽然这很昂贵,但我们无法提前预测所有所需的功能并对表进行反规范化。(jaypipes 提供了此模式: http://pastie.org/1515576)
虽然某些键将是二进制性质的: is-enabled, can-run-windows, accept-migrations,其他键将是基于浮点数的并且动态变化(尤其是主机功能)。例如: free-disk, average-load, number-of-instances 等。
主机将将其存在发布到调度器队列,以让调度器了解主机的当前状态。这样,不需要在数据库中为主机条目,并且主机可以在不导致数据库完整性问题的情况下上线/下线。
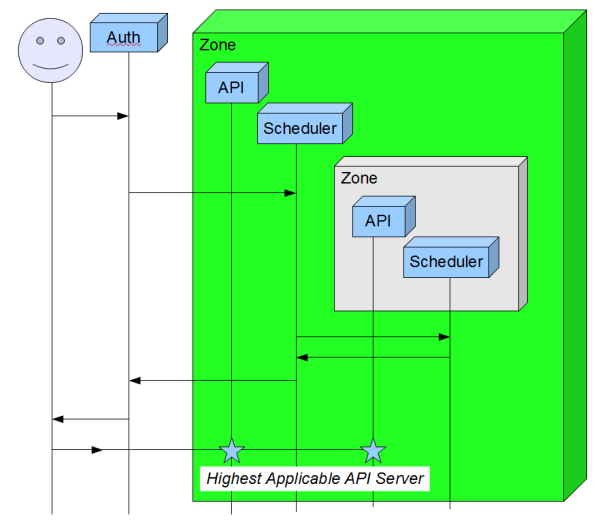
选择正确的 API 服务器
如前所述,Auth 服务告诉客户端使用哪个 API 服务进行后续操作。为了减少队列中的聊天,我们希望将客户端发送到包含该客户端管理的所有实例的最低级别区域。我们的意图是使用相同的区域间通信通道来做出此决定。
Auth 服务始终从顶级区域进入并询问“您管理客户端 XXXX 吗?” 此请求将向下沉到每个嵌套区域,如果找到匹配项,则返回。如果多个子区域响应“是”,则返回父区域 API。如果单个子区域响应“是”,则返回该区域的 API 服务。如果没有任何子区域响应,则该区域返回“否”,其父区域做出决定。
此信息可以在后续实现中进行缓存。这可以在创建、迁移或删除实例时预先计算。
用户故事
todo
实现
本节应描述一个行动计划(“如何”)以实施所讨论的更改。
Cactus 的意图是在 Sprint-1(前 3 周)中致力于数据模型、api 和相关的客户端工具,然后在 Sprint-2 中致力于队列间通信。
Sprint 1 任务
zone-add(api_url, username, password) zone-delete(zone) zone-list zone-details(zone)
Nova API
GET /zones/ GET /zones/#/detail POST /zones/ PUT /zones/# DELETE /zones/#
DB
add_zone(...) delete_zone(...)
未解决的问题
这应该突出显示需要在进一步的规范中解决的任何问题,而不是规范本身的问题;因为任何存在问题的规范都无法获得批准。
BoF 议程和讨论
使用本节记录 BoF 期间的笔记;如果将其保留在批准的规范中,请用于总结讨论内容并记录任何被拒绝的选项。
RabbitMQ 峰值结果
在 12G、四核双 i7 PC 上运行 VMWare Ubuntu 10.10 实例 (256M, 1 cpu)。
https://github.com/SandyWalsh/rabbit-test
并行“add”: 客户端在 Node 1 上运行 (Warn 级别)
无集群 (2.3)
1 个 Worker
Finished 1/1 in 0:00:00.192947 (avg/req 0:00:00.192947) Finished 10/10 in 0:00:00.901358 (avg/req 0:00:00.090135) Finished 100/100 in 0:00:08.180311 (avg/req 0:00:00.081803) Finished 1000/1000 in 0:01:20.539726 (avg/req 0:00:00.080539) Finished 10000/10000 in 0:13:26.883584 (avg/req 0:00:00.080688) --didn't do more--
2 节点集群 (2.3)
1 个 Worker/节点
Finished 1/1 in 0:00:00.157986 (avg/req 0:00:00.157986) Finished 10/10 in 0:00:00.411800 (avg/req 0:00:00.041180) Finished 100/100 in 0:00:02.256900 (avg/req 0:00:00.022569) Finished 1000/1000 in 0:00:21.738734 (avg/req 0:00:00.021738) Finished 10000/10000 in 0:03:37.536059 (avg/req 0:00:00.021753) Finished 100000/100000 in 0:34:32.088134 (avg/req 0:00:00.020720)
3 节点 Rabbit 集群 (1.8)
2 个 Ram 节点,1 个磁盘节点
Finished 1/1 in 0:00:02.347252 (avg/req 0:00:02.347252) Finished 100/100 in 0:00:03.300854 (avg/req 0:00:00.033008) Finished 1000/1000 in 0:00:17.758042 (avg/req 0:00:00.017758) Finished 10000/10000 in 0:02:50.025154 (avg/req 0:00:00.017002) Finished 100000/100000 in 0:29:52.013909 (avg/req 0:00:00.017920)
3 个节点 - 故障条件
Finished 1000/1000 in 0:00:16.667371 (avg/req 0:00:00.016667) - no failures Finished 1000/1000 in 0:00:24.568783 (avg/req 0:00:00.024568) - 1 worker killed, no loss Finished 1000/1000 in 0:00:35.739763 (avg/req 0:00:00.035739) - 2 workers killed, no loss
杀死一个 Rabbit 节点 - Boom: http://paste.openstack.org/show/630/ ... 客户端修复需要。
sudo rabbitmqctl stop_app
asksol 说 join() 不支持 Kombu 的新错误处理功能。重新应用 join() 不起作用。
2 个节点在 DC
都在 DFW1。Worker 在 DFW1b 上
Finished 1/1 in 0:00:00.235317 (avg/req 0:00:00.235317) Finished 10/10 in 0:00:00.346868 (avg/req 0:00:00.034686) Finished 100/100 in 0:00:01.812593 (avg/req 0:00:00.018125) Finished 1000/1000 in 0:00:17.602759 (avg/req 0:00:00.017602) Finished 10000/10000 in 0:02:54.620607 (avg/req 0:00:00.017462)
3 个节点跨越 3 个 DC
2 个在 DFW1,1 个在 ORD。Workers 在 DFW1b 和 ORD
Repeated problems with dropped connections. Finished 1/1 in 0:00:00.752433 (avg/req 0:00:00.752433) Finished 10/10 in 0:00:04.470553 (avg/req 0:00:00.447055) Finished 100/100 in 0:00:41.711515 (avg/req 0:00:00.417115) Finished 1000/1000 in 0:06:33.388602 (avg/req 0:00:00.393388)
4 个节点跨越 4 个 DC
2 个在 DFW1,2 个在 ORD。3 个 workers: 1 个在 DFW1b,1 个在每个 ORD
每次都失败。AMQPConnectionException