Monasca/Transform-proposal
这是 Monasca Transform 提案的原始版本,大约在 Openstack Mitaka 时代。更新的文档可以在 docs.openstack.org 和 wiki.openstack.org/wiki/Monasca/Transform 找到。
monasca-transform:Monasca 的转换和聚合引擎
https://blueprints.launchpad.net/monasca/+spec/monasca-transform
- monasca-transform 项目是 Monasca 中的一个新组件,它将聚合和转换指标。
- monasca-transform 是一个数据驱动的聚合引擎,它根据业务需求收集、分组和聚合现有的 Monasca 单个指标,并将新的转换(派生)指标发布到 Monasca Kafka 队列。
- 由于新的转换指标以任何其他指标一样发布到 Monasca 中,因此可以设置和触发转换指标上的警报,就像任何其他指标一样。
问题描述
目前 Monasca 中没有机制来聚合/转换/派生和发布新指标。可以通过转换、聚合和发布 Monasca 中的新指标来解决几个用例
- 聚合单个指标
当前在每个主机或每个虚拟机的基础上可用的指标,例如 mem.total_mb 或 vm.mem.used_mb,可能需要将它们加总到所有主机或虚拟机,以便云操作员可以知道整个云中可用的总内存以及分配给所有虚拟机的总内存。
- 组合多个指标以派生新指标
可能需要从一个或多个指标派生指标,例如 cpu.total_logical_cores 和 cpu.idle_perc 是主机上的两个指标,可用于派生一个新指标,该指标将给出使用的 CPU 总数。 此外,这些主机使用的 CPU 可以进一步加总以找到整个云中正在使用的 CPU 数量。
- 查找指标在一段时间内变化的速度
可能需要计算指标值随时间变化的速度。 例如,要查找 swift 磁盘容量在一段时间内增加的速度,必须找到时间间隔开始时的磁盘使用量(例如小时开始时),然后找到时间间隔结束时的磁盘使用量(例如小时结束时),以确定磁盘使用量在此期间增加或减少的速度。
- 使用复杂的业务逻辑派生指标
可能需要对一组指标应用复杂的业务逻辑并派生新指标。 例如,考虑来自虚拟机周期性心跳指标,指示虚拟机处于什么状态。 必须查看虚拟机状态在目标时间间隔内的变化方式,然后使用一些业务逻辑来生成一个新指标,该指标将指示虚拟机处于可用状态的时间量。
拟议变更
拟议的 monasca-transform 组件框架将适应 Monasca 的微服务架构。 在其核心,它将从 Apache Kafka[1] 收集一段时间内可配置的一组指标,然后使用分组操作,运行一系列转换(或聚合)操作,这些操作可以包括简单的数学运算,如求和/最大/最小/平均值,或复杂的运算,如使用某些业务规则遍历组。 结果转换后的指标或一组转换后的指标将发布回 Apache Kafka。
我们从过去构建类似聚合框架来处理来自公共云服务的海量原始日志记录时发现了一些设计考虑因素,这些因素至关重要
- 可扩展、容错且高可用
由于我们将不得不收集、聚合和发布大量的指标,因此必须对指标处理进行扩展。 数据处理应该能够承受任何硬件故障,例如 CPU、内存或磁盘错误。 monasca-transform 过程应该是高可用的。 如果 monasca-transform 守护进程由于任何软件或硬件问题而在一台服务器上崩溃,则该框架应在另一台服务器上开始处理指标。
- 数据驱动的转换
转换框架必须是数据驱动的,并且应该可以通过配置更改为任何新指标添加新的转换。
- 可重用的组件和可重用的转换例程
各种指标的转换要求可能相似,因此一旦实现了转换例程,就应该能够为不同的指标集重用相同的转换组件和例程。
- 易于添加组件
添加新的转换组件应该简单明了。
- 灵活地更改和适应
随着时间的推移,业务需求和需求可能会发生变化。 为了满足这些要求,必须开发和添加新的转换组件或更新现有组件。 应该能够以最少的努力添加和更新组件。
- 单元测试
虽然转换例程可能很复杂,但应该能够为每个单独的转换组件编写单元测试,以确信组件的准确性。
替代方案
为了避免重复发明轮子,我们希望使用一个框架或工具,该框架或工具能够提供在商品机集群上处理数据,并具有工作分布、容错能力以及无缝承受节点故障的能力。
Hadoop 与 MapReduce/Yarn 满足这些要求,但需要某种稳定的存储,HDFS 并依赖于临时文件来保存中间处理状态,它们可能很慢。 它们还需要配置、安装、监控和维护集群中的许多组件,这通常是一项具有挑战性和艰巨的任务。 此外,很可能需要其他相关工具,如 Hive(用于类 SQL 数据处理)和 Pig(这将促进将 map reduce 作业表示为高级结构)。 使用其他工具会增加资源利用负担并增加开发时间。
Spark 允许使用 Python 表达作业,因此与 openstack 工具集非常吻合。 它已经证明比基于 Hadoop 的工具具有更高的处理速率,但允许重用现有的 mapreduce 类型知识。 Spark 正在获得势头和采用,并且可以利用这种上升趋势。 它还支持流式数据,这意味着我们可以专注于手头的任务而不是管道。 因此,它被选中作为处理框架。
架构
monasca-transform 将是一个基于 Apache Spark[2] 的数据驱动数据处理框架,用 python 实现。 Apache Spark[2] 是一个高度可扩展、快速、内存中、容错和并行数据处理框架。 所有 monasca-transform 组件都将用 python 实现,并使用 Spark 的 Python API 与 Spark 交互。
为了处理数据,monasca-transform 组件将使用 Spark 的转换操作,如 groupByKey()、filter()、map()、reduceByKey(),在 Spark 的弹性分布式数据集(也通常称为 RDD)上。 RDD 是 Spark 的分布式内存的基本抽象。
monasca-transform 将使用 Spark Steaming direct API 从 Kafka 队列中检索 Monasca 指标。 monasca-transform 将尽可能使用 Spark Data Frames 进行处理。 Spark Data Frames 使用新的查询计划器和分析器,称为 Catalyst,比可比较的 RDD 操作更有效和优化。
Data Frames 提供了一种更像 SQL 的数据操作能力,这也有助于从开发角度使用。 可以从 Spark RDD 转换为 Data Frame,反之亦然。 此外,Spark 为操作 RDD 和 Data Frame 都提供了通用的等效 API。
除了 Apache Spark 之外,monasca-transform 还将依赖于 MySQL 数据库表来存储处理和配置信息
- 处理信息:来自 Spark 批处理的 Kafka 偏移量,用于在发生故障或重新启动后恢复处理
- 配置信息:运行时参数和转换规范,用于驱动指标的转换和聚合
可以在多个节点上运行多个 monasca-transform 进程。 多个 monasca-transform 进程将使用 zookeeper 的领导者选举能力来选举一个主节点。 如果运行 monasca-transform 进程的主节点发生故障,则在另一个节点上运行的另一个 monasca-transform 进程将被选为领导者并开始处理数据。
以下是 monasca-transform 的组件
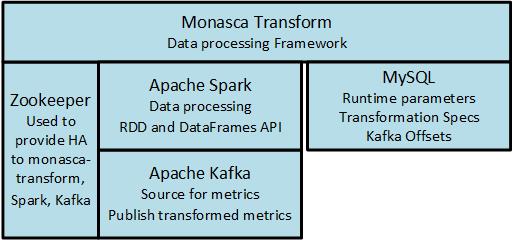
我们建议将 Spark 集群部署在独立集群模式下,以及 Monasca 的其他组件。 在最小配置中,例如在 devstack 部署中,主节点和工作节点都可以部署在单个节点上。 Spark 也可以部署在多个节点上,每个节点上运行多个主节点和工作节点。
逻辑处理数据流
monasca-transform 中的逻辑数据流可以大致分为两个不同的流,即输入指标转换为记录存储格式和使用一系列通用转换组件转换记录存储数据以派生转换后的指标数据。
转换为记录存储格式
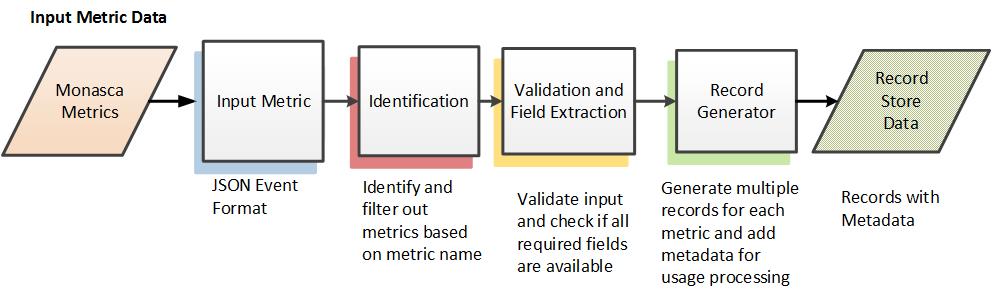
将输入指标转换为记录存储格式包括以下步骤
识别:识别和过滤掉不必要的指标。 这是通过将输入指标名称与配置数据存储中要转换的指标列表进行比较来完成的。 如果未识别输入指标,则在进一步处理中将忽略该指标。
验证和字段提取:通过检查指标 JSON 中是否存在预期的字段(预期的字段从配置数据存储中检索)来验证输入数据。 假设格式有效,则提取相关的字段。
记录生成器:提取的数据然后用于生成一个或多个新的内部处理指标和相关的元数据,这称为记录存储数据。 在输入原始指标必须以多种方式聚合的情况下,可以生成多个内部指标。
将输入指标转换为内部记录存储数据的优点是,其余处理不依赖于输入指标格式。 在未来,如果需要转换和聚合以新格式传入的数据,则需要编写新代码将新数据格式转换为记录存储,但其余处理管道将保持不变。
通用转换(聚合)以派生和发布新指标
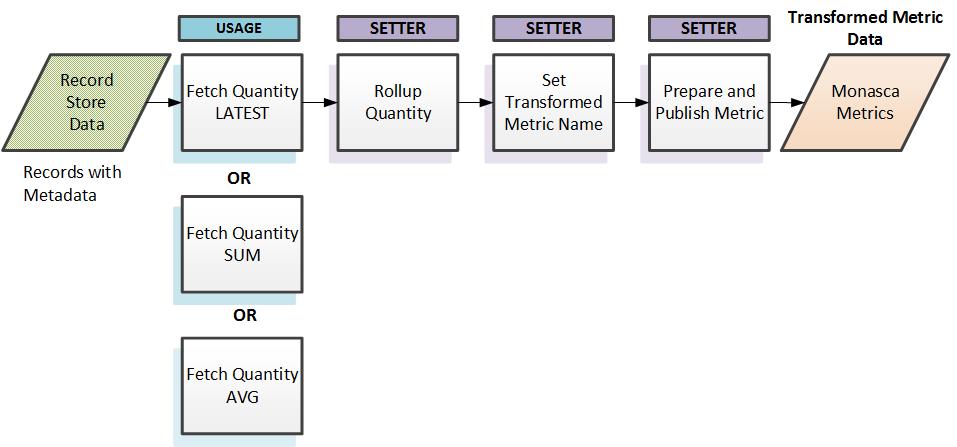
这是处理数据流的后半部分。 记录存储数据根据内部指标类型和配置数据存储中的规范路由到适当的处理组件。 然后执行其他处理。 处理包括使用用户定义的各种参数对记录存储中的数据进行分组,设置最终转换后的指标名称以及在新转换后的指标中设置适当的维度。 所有这些操作都由配置参数驱动。 然后将结果新的转换后的指标发布回 Apache Kafka。
数据模型设计
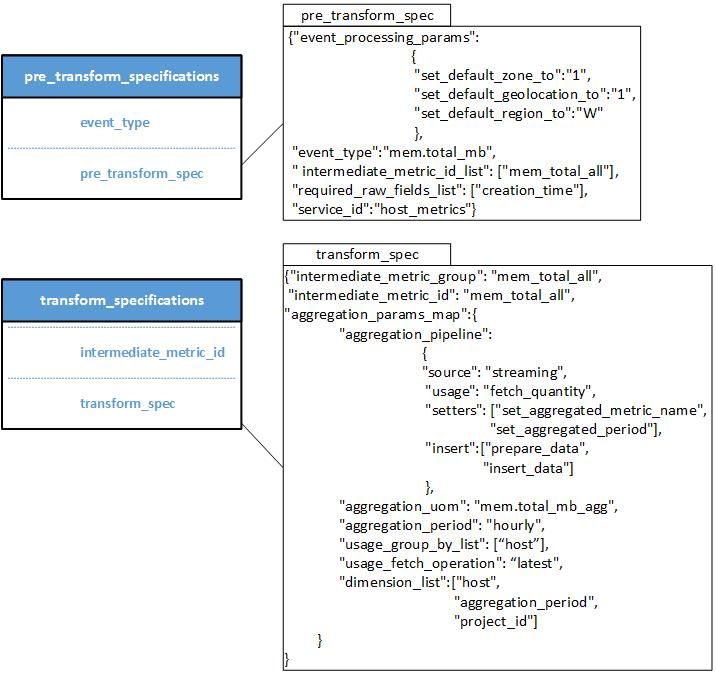
pre_transform_specifications 和 transform_specifications 表用于将输入指标转换为记录存储格式以及将记录存储数据转换为要发布到 Apache Kafka 的最终转换后的指标。
kafka_offsets 表存储由 Spark streaming direct Kafka API 检索到的偏移量信息,当它开始处理一个批处理时。 仅当批处理中的数据处理成功时,最新的偏移量信息才会更新到 kafka_offset 表中。 Spark 驱动程序在初始化时使用的最后一个保存的偏移量信息是从它停止的地方开始处理。
- pre_transform_specifications 表
- event_type:要处理的指标名称
- pre_transform_spec:JSON 格式的规范,用于帮助将数据处理为记录存储格式。 JSON 规范包含以下字段
- event_type:指标名称
- event_processing_params:键值对字典,用于帮助将输入指标转换为记录存储格式。 示例包括 set_default_region
- intermediate_id_list:内部指标的列表,由其标识符表示,输入指标应转换为这些指标。 在记录存储生成脚本期间,将从相同的输入指标生成多个内部指标。 每个内部指标可以使用不同的处理管道进行转换。
- required_raw_fields_list:JSON 路径字符串列表,将在验证期间用于检查它们是否存在且不为空。
- service_id:服务标识符,标识此输入指标属于哪个服务。
- transform_specs 表
- metric_id:表示内部处理指标的标识符
- transform_spec: 以 JSON 格式指定的规范,定义了处理流水线和运行时参数,这些参数将被处理流水线组件使用。JSON 规范包含以下字段
- aggregation_params_map: 键值对,代表处理流水线和运行时参数。
- aggregation_pipeline: 处理流水线规范的 JSON 表示形式,以及处理流水线中组件使用的任何运行时参数,例如 aggregation_group_by_list
- kafka_offsets 表
- topic: 正在收集和存储偏移量的 Kafka 主题
- until_offset: 偏移量范围的结束位置
- from_offset: 偏移量范围的起始位置
- app_name: 代表这些偏移量正在被存储的应用程序的名称。
- partition: 分区标识符
通用转换组件的设计
通用转换组件将是可重用的组件,可以组装成复杂的转换流水线。每个通用组件将作为 Python 类实现,并且可以调用多个 Spark 转换。相同类型的通用组件将实现接受标准参数集并返回标准 Spark RDD 的函数。Source、Usage 和 Setter 是几个通用的组件类型。
所有 usage 组件将实现一个名为 'usage' 的 Python 函数,该函数接受 'transform_context' 和 'record_store_dataframe' 作为参数,并返回一个 'instance_usage_dataframe'。 类似地,所有 setter 组件将实现一个名为 'setter' 的函数,该函数接受 'transform_context' 和 'instance_usage_dataframe' 作为参数,并返回一个修改后的 'instance_usage_dataframe'。 组件接口通过输入和输出类型标准化,以允许可插拔性。
通用转换组件是可扩展的,必要时可以添加新组件。 例如,如果需要某种转换例程通过发出 REST API 调用来查找值,则可以开发一个新的 setter 组件,该组件实现标准的 "setter" 函数接口。 由于新的 setter 组件符合 Setter 组件接口,因此可以在任何先前的 setter 组件之前或之后添加此新组件。 可以通过使用这些可插拔组件的系列通过转换规范来构建复杂的转换流水线。
| 组件类型 | 组件简称 | 组件描述 | 参数 | 返回值 |
|---|---|---|---|---|
| 用法 | fetch_quantity | 根据 usage_group_by_list 对 record_store_data_frame 记录进行分组,这些记录由中间指标 ID 表示,然后执行 usage_fetch_operation 参数指示的操作。 | transform_context, record_store_data_frame | instance_usage_data_frame |
| fetch_quantity_util | 根据 usage_group_by_list 和 usage_fetch 操作对 record_store_data_frame 记录进行分组,以查找已使用的数量,用于数量和利用率百分比。 | transform_context, record_store_data_frame | instance_usage_data_frame | |
| Setter | rollup_quantity | 根据 setter_group_by_list 参数对 instance_usage_data_frame 数据进行分组,然后执行 setter_fetch_operation 参数指示的操作 | transform_context, instance_usage_data_frame | instance_usage_data_frame |
| set_aggregated_metric_name | 遍历 instance_usage_data_frame 数据并设置 aggregation_uom 参数指示的指标名称 | transform_context, instance_usage_data_frame | instance_usage_data_frame | |
| Insert | insert_data | 通过根据 setter_dimension_list 参数设置维度,准备最终转换的指标 JSON,并将数据发布到 Kafka "metrics" 主题 | transform_context, instance_usage_data_frame | instance_usage_data_frame |
通用转换组件易于编写和维护。 除了可重用之外,这些通用转换组件还可以组合起来创建复杂的转换例程或流水线。 可以编写 Python 中的单元测试来单独测试每个组件,也可以测试复杂的转换例程。
输入指标的转换示例
下表列出了输入指标的转换步骤
| 步骤 | 组件 | 描述 | Spark 转换 | 笔记 |
|---|---|---|---|---|
| 1 | 检索输入指标('583d49ab6aca482da653dd838deaf538load.avg_5_minhostnamedevstack',
'{"metric":{"name":"mem.total_mb",
"dimensions":{"service":"monitoring",
"hostname":"mini-mon"
},
"timestamp":1453308000000,
"value":5969.0},
"meta":{"tenantId":"583d49ab6aca482da653dd838deaf538",
"region":"useast"},
"creation_time":1453308005}')
|
从 Kafka 拉取的传入 Monasca 指标元组 | -- | |
| 2 | 调用输入指标到记录存储转换器 | 将传入的指标转换为记录存储数据框 |
//pseudo code KafkaUtils.createDirectStream //Spark Streaming API get discretized stream from kafka DStream.transform() //to pull offsets raw_metrics_df = inputDStreamRDD.map() //to extract the JSON metric from the tuple, and convert to dataframe pre_transform_df = pre_transform_specs.jsonRDD() //convert to pre_transform_specs into data frame filtered_metrics_df = raw_metrics_df.join(pre_transform_df).where(event_type=metric_name) //join raw data with pre transform specs df to filter out unwanted raw metrics validated_df = filtered_metrics_df.validate() //validate metrics, check for required fields from pre_transform_spec for this event type record_store_df = validated_df.explode() //generate multiple records for each intermediate metrics from pre_transform spec's intermediate_metric_id_list |
从 Kafka DStream 中提取 Kafka 偏移量信息,过滤、验证并生成记录存储数据框格式的记录 |
| 3 | 处理记录存储数据中的指标 | 从记录存储数据框中找到中间指标,并为每个指标找到转换规范中的转换流水线,并调用转换规范中 aggregation_pipeline 参数表示的每个组件 | -- | 创建一个 transform_context 对象,其中包含 Kafka 偏移量信息和任何配置属性 |
| 4 | 调用 fetch quantity usage 组件 | fetch_quantity (最新) 查找一小时的最新数量 |
fetch_latest(transform_context, record_store_data) {
//pseudo code
grouped_sorted_df = record_store_df.groupBy("host", "event_date", "event_hour") and sort group by timestamp
latest_grouped_sorted_df = grouped_sorted_df: get latest in each group
instance_usage_df = convert latest_grouped_sorted_df to instance_usage_df
return instance_usage_df
}
|
|
| 5 | 调用 Set Aggregated Metric Name 组件 | 设置最终聚合指标名称 |
set_aggregated_metric_metric_name(transform_context, instance_usage_df) {
//pseudo code
instance_usage_df = instance_usage_df.map(transform_context.transform_spec.aggregated_uom)
return instance_usage_df
}
||
| |
| 6 | 调用 Insert Kafka 组件 | 将 instance_usage_df 转换为指标 JSON 并发布到 Kafka |
insert_data(transform_context, instance_usage_df) {
//pseudo code
//convert to json and set proper dimensions
instance_usage_json_list = convert_to_metrics_json(instance_usage_df,
transform_context.transform_specs.aggregaton_dimensions)
kafka_publisher.publish(instance_usage_json_list) //publish metrics to kafka
}
|
REST API 影响
当前 Monasca API 将不会发生变化。
安全影响
monasca-transform 使用 Spark Streaming 连接到 Kafka 中的 "metrics" 主题以检索指标进行处理。 monasca-transform 将代表在配置文件中可以设置的租户将转换后的指标写回 Kafka。 租户应具有适当的 monasca-admin 角色,以便将数据持久化到 Monasca 数据存储中。 Spark Web 用户界面以及主节点和工作节点之间的连接可以使用 ACL 和加密[4] 进行保护。 目前尚不支持连接到 Kafka 和加密,但目前正在进行工作以在 Kafka 中提供对此的支持[4]。
其他最终用户影响
通过 Monasca API,新的转换后的指标将在 Monasca 中可用。
性能/可扩展性影响
- 由于新的转换后的指标将被写回 Kafka 中的 "metrics" 主题,因此在增加要持久化的指标方面会产生一些影响。 这不应该产生任何重大影响,因为转换/聚合的指标数量必然会比整体传入指标的数量少得多。
- 鉴于转换后的指标数量明显较少,它们不应对数据保留策略产生任何明显影响。
- Spark 主节点和工作节点必须在部署 monasca-transform 的节点上配置和安装(最有可能与 Monasca 的其他组件一起部署,但并非必需),并且必须为 Spark 主节点、工作节点和执行器进程分配资源,例如 CPU 和内存。 此外,monasca-transform Python 组件必须配置和部署。 部署 Spark 和 monasca-transform 会在增加运行它的节点上的负载方面产生一些影响。 必须评估这种影响。
- 在可扩展性方面,如果需要处理的指标数量增加,可以跨其他节点水平扩展 Spark 工作节点。
其他部署者影响
monasca-transform 必须通过配置文件进行配置。 配置选项包括指向 Zookeeper 的指针、Spark Streaming 使用的批处理间隔、将指标提交到 Kafka 的租户 ID 以及 Spark Master 信息,以便 monasca-transform 可以将作业提交到 Spark 集群。 还有访问 MySQL 数据库以从驱动表拉取信息的配置选项。
此外,安装 monasca-transform 的部署者还必须安装 Spark worker、Spark master 和 monasca-transform 进程的启动/停止脚本。 部署者还必须将预转换规范和转换规范插入 MySQL 驱动表。
monasca-transform 将是 Monasca 中的可选组件,用户可以选择安装或不安装。 正在编写一个 devstack 插件,该插件将提供安装 monasca-transform 和 Spark 的方法,以及一个 tempest 测试。 这将能够验证 monasca-transform 是否正常工作。 这可用于 CI/CD 处理。
开发人员影响
想要编写自己的转换例程来聚合新指标的开发人员必须在转换规范 JSON 中编写新的预转换规范,并将它们添加到驱动表。 为了添加新的转换组件,开发人员必须编写实现适当接口(例如 usage、setter、insert 等)的 Python 模块,并使用 Spark 转换来操作和/或将数据写回 Kafka。 新组件还必须添加到 setup.cfg,以便可以加载和利用新组件。
实现
Assignee(s)
主要负责人
待定
其他贡献者
待定
持续维护者
待定
工作项
- 连接到 Kafka 并检索指标、检索偏移量并将偏移量存储在 MySQL 数据库中的 Spark 驱动程序
- 定义预转换规范和转换规范表以及填充这些表的代码
- 定义预转换规范和转换规范 JSON
- 识别、验证和转换输入指标为记录存储记录
- 通用转换构建器,它将调用流水线的转换组件
- 实现通用转换 usage 组件和 fetch_quantity、fetch_quantity_util 和 fetch_quantity_rate_of_change 的单元测试
- 实现通用转换 setter 组件和 rollup_quantity、set_aggregated_metric_name 的单元测试
- 实现插入 Kafka 组件以将聚合指标写入 Kafka
- 实现更多转换规范以转换更多指标
未来生命周期
阶段 1:处理流数据:处理通过 Kafka 队列传入的指定时间间隔内的传入指标数据
阶段 2:处理流数据+持久化数据:处理通过 Kafka 传入的数据以及已经持久化并可用于 Monasca 数据存储中的数据。 这需要实现可以与 Monasca 通信的 Spark 连接器/插件(类似于 Spark 与 cassandra、hbase 集成的方式)
依赖项
Apache Spark 1.6.0
Zookeeper
测试
将编写 Python 单元测试来单独测试整个转换流水线的每个组件,以及测试部分或整个转换流水线。 将开发一个 devstack 插件来安装 monasca-transform 和 Spark。 还需要编写一个 tempest 测试来测试 monasca-transform 组件的工作情况,该测试可用于 CI/CD 流程。 此测试将配置转换规范表,然后为一些传入指标运行转换并检查 Monasca 中是否存在新的转换后的指标。
文档影响
monasca-transform 是一个新组件,必须在 Monasca Wiki 上详细记录。 架构、典型部署、配置选项和依赖项必须进行广泛记录。
参考文献
1 Apache Kafka kafka.apache.org
2 Apache Spark spark.apache.org
3 Spark Security spark.apache.org/docs/latest/security.html
4 Kafka Security cwiki.apache.org/confluence/display/KAFKA/Security