边缘环境中的镜像处理
此页面包含关于温哥华论坛讨论该主题的摘要。讨论的完整记录在 此处。边缘云基础设施的特性和需求在 OpenStack_Edge_Discussions_Dublin_PTG 中描述。
图表的来源是 此处。
目录
同步策略
- 将每个镜像复制到每个边缘云实例:最简单但效率最低的解决方案
- 仅将镜像复制到需要它们的边缘云实例
- 为镜像提供同步策略
- 依赖镜像的拉取
- 根据 clarkb 的说法,nodepool 在这里可能是一个不错的选择。它将积极尝试确保您想要的镜像位于您想要的所有位置。
Glance 的当前架构选项
本节包含当前正在查看的 Glance 架构的更新视图。
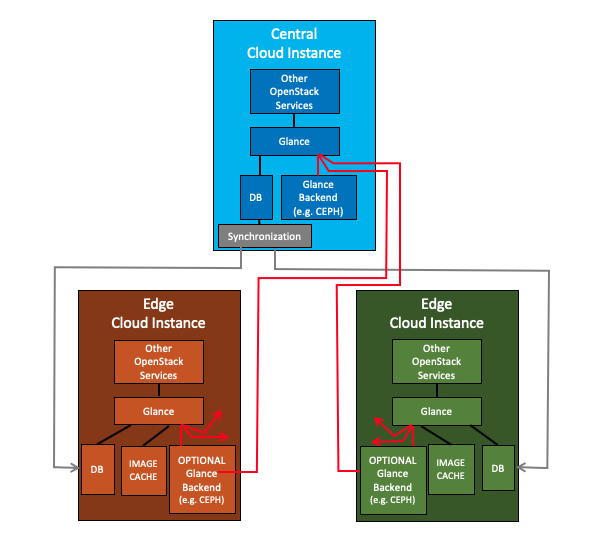
具有 1 个或多个后端和同步数据库的 Glance(可选带缓存)
注意:当前推荐的解决方案是使用单个共享的中央后端,启用数据库同步和镜像缓存。额外的后端将是一种增强功能。
描述
- 中央 Glance 具有多个后端,对所有后端具有读写访问权限
- 一个本地后端(默认后端),以及
- Nx 个远程后端;每个 Nx 个边缘云一个;
- 每个边缘云 Glance 具有 Nx 个后端,对这些后端具有只读访问权限
- 一个本地后端(默认后端),
- 一个远程后端;中央 Glance 的本地后端,以及
- (N-1)x 个远程后端;其他边缘云的本地后端。
- 注意:假设中央和边缘之间的 Glance 数据库已复制,在 Glance 前端之间共享后端应该很少或没有工作。
- 中央 Glance 的读写数据库(包括元数据)正在复制到边缘云 Glance 的只读数据库,
- 中央 Glance 的用户
- 将镜像添加到中央 Glance,到中央位置的默认后端,
- 需要不同边缘云站点上的镜像,手动复制到代表这些站点的远程后端。
- 注意:镜像在后端之间复制的能力是多个 Glance 后端工作之上的增量工作。
- 边缘 Glance 的用户
- 具有对 Glance 数据库和所有后端的只读访问权限
- 访问存储在此边缘本地后端的镜像
- 速度快,并且
- 在与其它站点失去连接时仍然可以访问。
- 访问存储在中央后端(或其他边缘后端)的镜像
- 速度慢,
- 在与其它站点失去连接时无法访问,
- 尽管如此,如果启用了缓存,镜像将被缓存以加快后续镜像的使用速度。并且缓存的镜像在与其它站点失去连接时可以访问。这基于现有的缓存能力和 Glance 数据库正在复制的假设。
优点
- 利用现有和/或计划的 Glance 功能,
- 从技术上讲,边缘后端可以是可选的。可以仅使用中央 Glance 的后端,并且在边缘 Glance 中没有本地边缘后端来实现该解决方案,从而依赖于缓存来实现边缘云的隐式可用性。
- 多个后端提供了更多的可靠性,以确保所需的镜像在断开连接时在边缘可用。例如,边缘的先前缓存的镜像可能会在边缘缓存另一个镜像时被不知不觉地从缓存中清除,然后在与中央站点断开连接时不可用。
缺点
- 多个后端方法需要手动将镜像推送到/复制到边缘云。必须主动知道每个边缘站点上需要的镜像。
- 多个后端方法需要在中央云 Glance 上为每个新添加的边缘云进行显式配置,
- 我不相信所有 Glance 后端类型都将受支持,例如本地文件后端将不受支持。只有那些按定义可远程访问的后端才能工作。
- 边缘 Glance 必须意识到并配置了中央 Glance 后端的详细信息。(与主要提案不同,在主要提案中,中央 Glance 后端对边缘 Glance 是透明的。)
- 多个后端必须显式支持扩展支持的后端数量到所需的边缘云数量,这可能在 100 或 1,000 范围内。
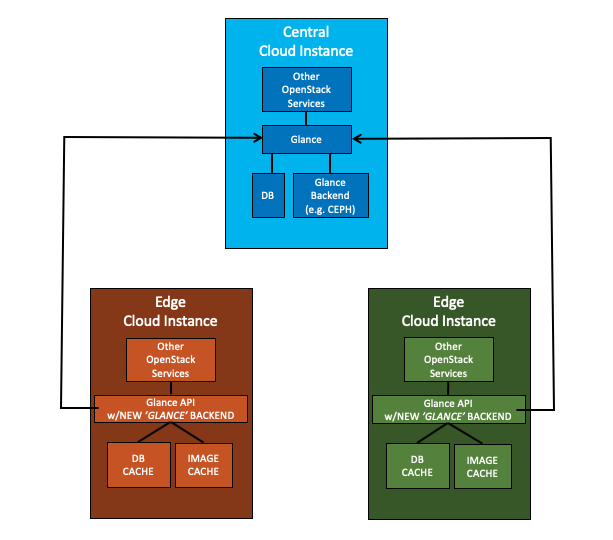
使用中央 Glance 作为后端的边缘 Glance(带缓存)
描述
- 中央 Glance 是一个完整的典型 Glance 部署,
- 边缘 Glance 是一个 Glance API,使用一种“NEW”数据访问/后端类型,即远程 Glance(在本例中为中央 Glance),
- 边缘 Glance 使用中央 Glance 的 API,访问中央 Glance 中的镜像和镜像元数据,
- 边缘 Glance 将本地缓存镜像和镜像元数据,
- 边缘 Glance 在与后端(即中央 Glance)断开连接时,将使用镜像元数据缓存和镜像缓存来服务本地请求。
优点
- 不需要任何显式的数据库同步;一切都通过缓存完成,
缺点
- 需要 Glance 更改,而这些更改目前尚未计划,
- 为了准备潜在的连接丢失,维护缓存同步需要进行审计以保持缓存同步,这会消耗宝贵的资源,
- 根据 Keystone 解决方案,边缘 Glance 与中央 Glance 的身份验证可能需要额外的身份验证步骤,
Glance 的先前架构选项
图例
具有多个后端的 Glance - 拉取模式
有一个中央 Glance,能够处理多个后端。每个边缘云实例都由中央 Glance 中的 Glance 后端表示。每个边缘云实例运行一个 Glance API 服务器,该服务器配置为使用中央 Glance 拉取镜像,但也使用本地缓存。所有 Glance API 服务器使用共享数据库,数据库集群不在 Glance 的责任范围内。每个 Glance API 服务器可以访问彼此的镜像,但默认使用自己的镜像。访问远程镜像时,Glance API 会从远程位置流式传输镜像。(从这个意义上说,这是拉取模式)。边缘云实例中的 OpenStack 服务使用 Glance 后端中的镜像,并使用直接 URL。
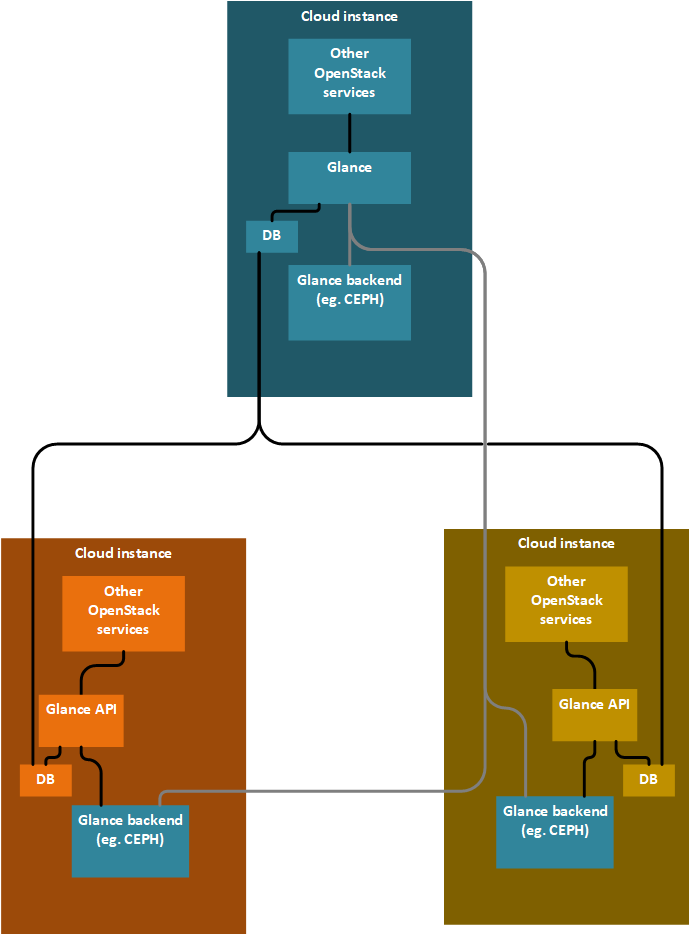
已经使用 etherpad 和 spec 开始了多个后端的工作。如果中央 Glance 能够协调镜像的同步,则级联(一个边缘云实例同时是接收器和镜像的源)是可能的。
- 疑虑/问题
- 网络分区容错性?
- 首次启动给定镜像时需要网络连接。
- 将数据库凭据存储在远端边缘是否安全?(在没有网络连接的情况下无法提供镜像访问,并且无法将数据库凭据存储在边缘云实例中)
- 在这种情况下是不可避免的。
- 边缘云实例中的 OpenStack 服务可以使用来自本地 Glance 的镜像吗?担心 OpenStack 服务(例如 nova)仍然需要通过仅在中央站点上可用的 Glance API 获取直接 URL。
- 可以通过允许 Glance 访问所有 CEPH 实例作为后端来避免这种情况
- CEPH 后端是 CEPH block 还是 CEPH RGW?
- Glance 直接与 CEPH block 通话。或者,可以使用 Swift 从 Glance 使用,并使用 CEPH RGW 作为 Swift 后端。
- 我理解正确吗,CEPH 后端处于复制配置中?
- 不总是
- 网络分区容错性?
- 优点
- 基于当前的 Glance 架构实现起来相对容易
- 边缘云实例上的存储需求较小
- 镜像会自动从中央 Glance 加载到边缘云实例
- 缺点
- 需要每个边缘云实例中相同的 Glance 后端
- 需要每个边缘云实例中相同的 OpenStack 版本(在升级期间除外)
- 对网络连接丢失的敏感性尚不清楚
- 无法显式控制镜像缓存的时间段
- 无法使镜像从缓存中失效
- 必须将 Glance 数据库凭据存储在每个边缘云实例中
- 镜像被拉取
具有多个后端的 Glance - 分布式存储
有一个中央 Glance,能够处理多个后端。每个边缘云实例都由中央 Glance 中的 Glance 后端表示。每个边缘云实例运行一个 Glance API 服务器,该服务器配置为使用中央 Glance 拉取镜像,但也使用本地缓存。所有 Glance API 服务器使用共享数据库,数据库集群不在 Glance 的责任范围内。存储后端支持集群,并且在每个边缘云实例中可用。存储的集群不在 Glance 的范围内。OpenStack 服务在边缘云实例中使用 Glance 后端中的镜像,并使用直接 URL。
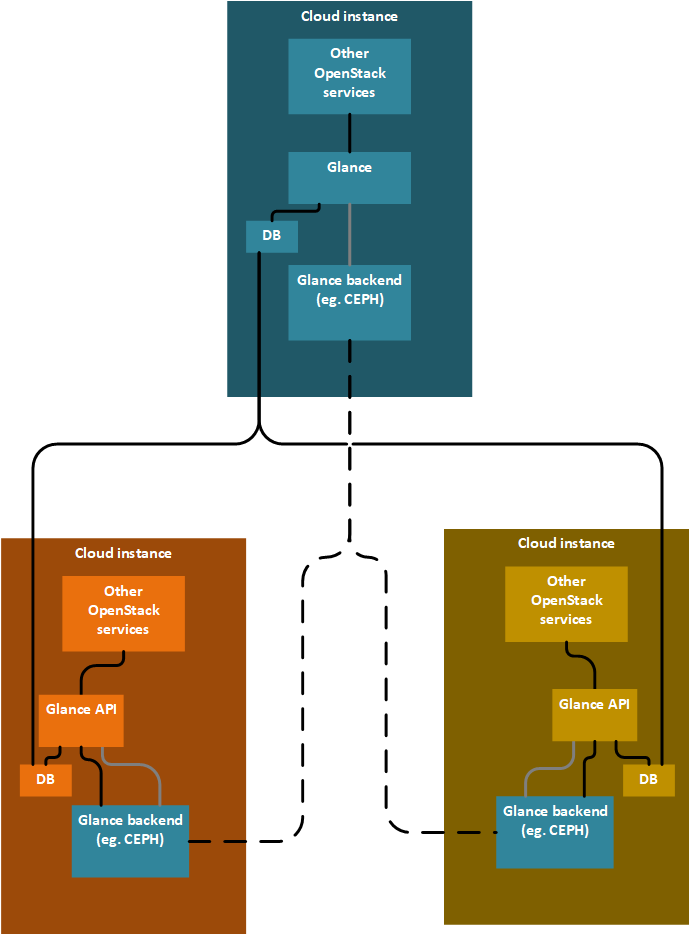
已经使用 etherpad 和 spec 开始了多个后端的工作。在 Rocky 中,已经支持多个后端,但它们必须是不同的类型。支持相同类型多个后端尚未实现。如果中央 Glance 能够协调镜像的同步,则级联(一个边缘云实例同时是接收器和镜像的源)是可能的。
- 疑虑/问题
- 优点
- 基于当前的 Glance 架构实现起来相对容易
- 缺点
- 需要每个边缘云实例中相同的 Glance 后端
- 需要每个边缘云实例中相同的 OpenStack 版本(在升级期间除外)
- 对网络连接丢失的敏感性尚不清楚
- 每个镜像都复制到每个边缘云实例
- 必须将 Glance 数据库凭据存储在每个边缘云实例中
- 添加新的边缘云实例需要重新配置分布式数据库
具有独立同步服务的多个 Glance,通过 Glance API 同步
每个边缘云实例都有其 Glance 实例。有一个同步服务,能够指示 Glance 执行同步。镜像数据的同步是通过 Glance API 完成的。
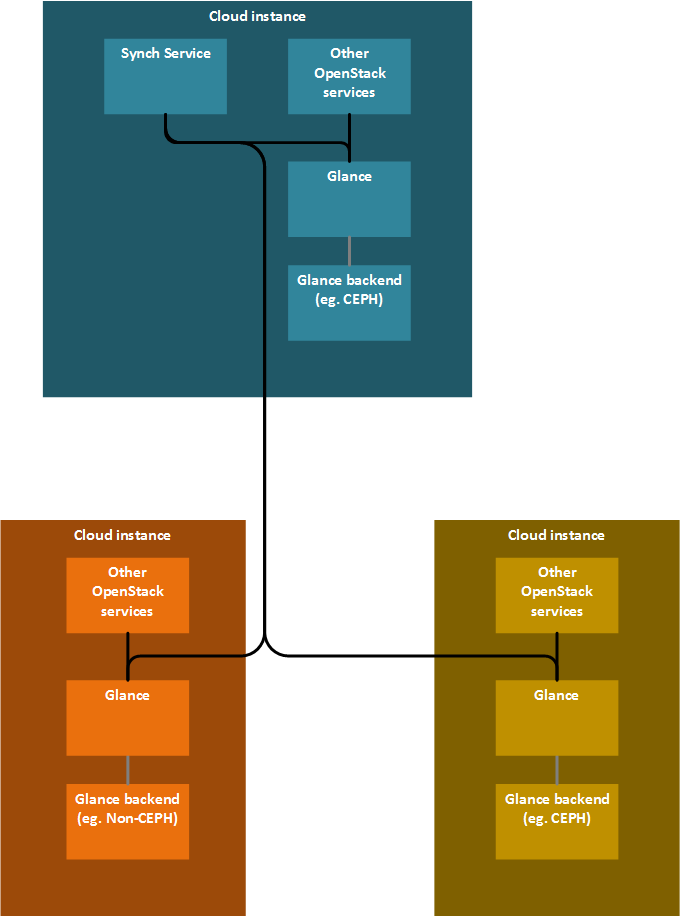
级联仅对同步服务可见,对 Glance 不可见。
- 优点
- 每个边缘云实例可以具有不同的 Glance 后端
- 可以支持不同边缘云实例中的多个 OpenStack 版本
- 可以扩展以支持多种 VIM 类型
- 使用 API 提供对元数据模式更改的支持
- 缺点
- 需要新的同步服务
- 目前某些元数据对 API 用户不可见,并且无法将元数据分配给镜像
具有独立同步服务的多个 Glance,使用后端同步
每个边缘云实例都有其 Glance 实例。有一个同步服务,能够指示 Glance 执行同步。镜像数据的同步由后端负责(例如:CEPH)。 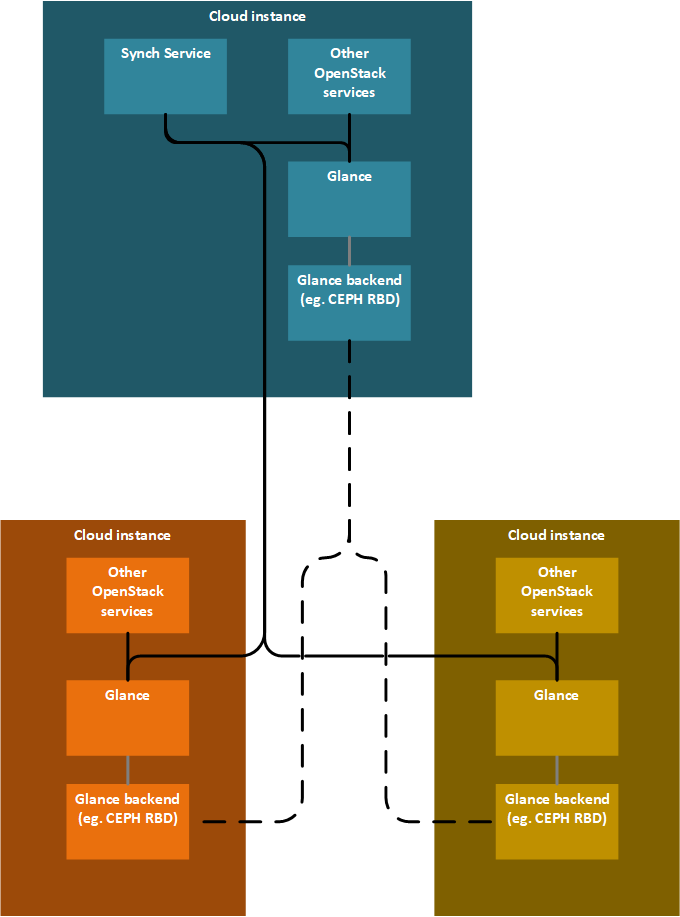
级联仅对同步服务可见,对 Glance 不可见。
- 疑虑/问题
- 图中的 CEPH 后端是 CEPH block 还是 CEPH RBD?
- CEPH RBD
- 图中的 CEPH 后端是 CEPH block 还是 CEPH RBD?
- 优点
- 缺点
- 需要新的同步服务
一个 Glance 和多个 Glance API 服务器
有一个中央 Glance,每个边缘云实例运行一个单独的 Glance API 服务器。这些 Glance API 服务器与中央 Glance 通信。后端由中央访问,边缘云实例中只有缓存。Nova Image Caching 在计算节点上缓存,对于一体化边缘云或小型边缘云来说效果很好。但是 glance-api 缓存在边缘云级别缓存,因此更适合具有大量计算节点的大型边缘云。
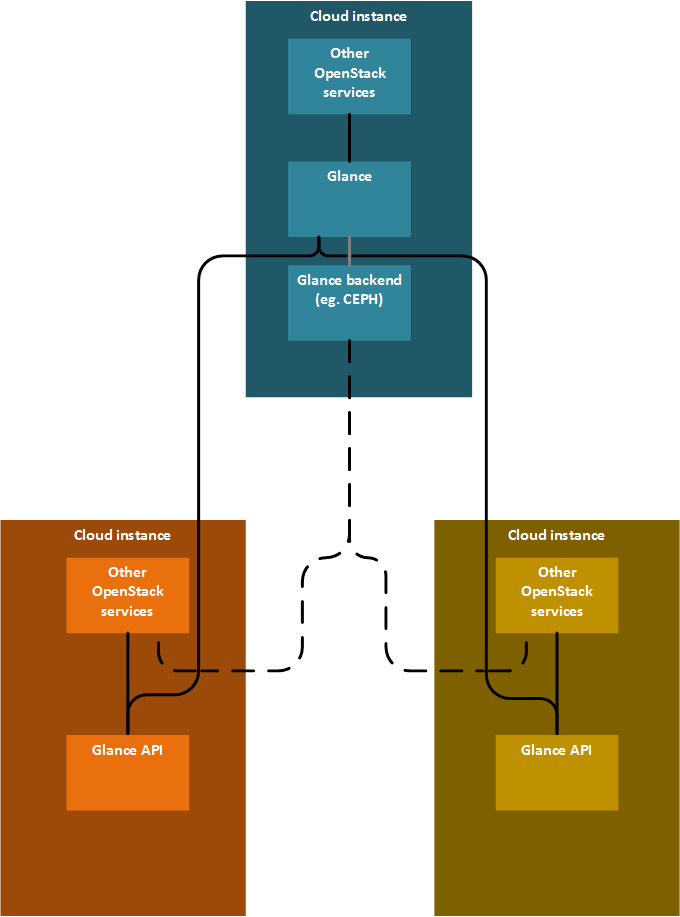
在 幻灯片 中有描述。由于仅使用拉取策略,因此无法进行级联。
- 疑虑/问题
- 我们计划使用 Nova 镜像缓存还是 Glance API 服务器中的缓存?
- 镜像元数据是否也缓存在 Glance API 服务器中,还是仅缓存镜像?
- 优点
- 隐式的位置感知
- 缺点
- 首次使用镜像总是需要很长时间
- 如果与中央 Glance 的网络连接出现错误,Nova 将可以访问镜像,但将无法确定用户是否有权使用镜像,并且将没有指向镜像数据的路径
- 目前 Glance API 缓存不支持元数据缓存。
Glance 的边缘场景
以下两个场景描述了从 Glance 镜像启动 Nova 实例的流程,分别采用分布式和集中式控制架构。
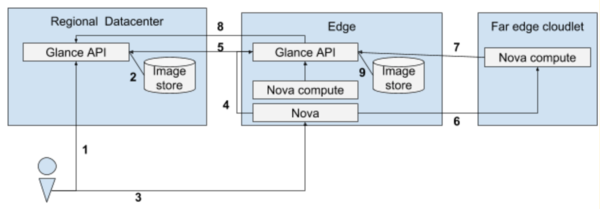
此场景描述了如何在边缘站点上启动 Nova 实例,以及镜像在边缘站点上进行缓存时需要缓存元数据的方式。
- 用户将镜像上传到区域数据中心的 Glance
- Glance 存储镜像
- 用户调用 Nova 启动实例,传递新镜像的镜像名称或 ID
- Nova 调用边缘站点的 Glance,查看镜像是否存在
- Glance 检查本地是否具有镜像
- 如果 Glance 没有镜像,它将调用区域数据中心的 Glance 确认镜像是否存在(转到第 6 步)
- 如果 glance 确实拥有该镜像,并且镜像的 updated_at 时间大于 glance 缓存 TTL,那么它将调用主数据中心的 glance 来确认元数据是否仍然相同。如果不同,它将更新其元数据的副本。
- Nova 通知 nova-compute 启动实例
- Nova-compute 调用 glance 获取镜像
- 如果 glance 没有该镜像,它将调用区域数据中心的 glance 下载镜像(转到步骤 8)
- 如果 glance 确实拥有该镜像,并且镜像的 updated_at 时间大于 glance 缓存 TTL,那么它将调用区域数据中心的 glance 更新其元数据的副本(转到步骤 8)
- 如果 glance 拥有该镜像并且 updated_at 时间小于 TTL,则转到步骤 10
- 边缘数据中心的 glance 调用区域数据中心的 glance 下载镜像及其元数据
- Glance 本地存储镜像
- Glance 将镜像返回给 nova-compute,实例启动
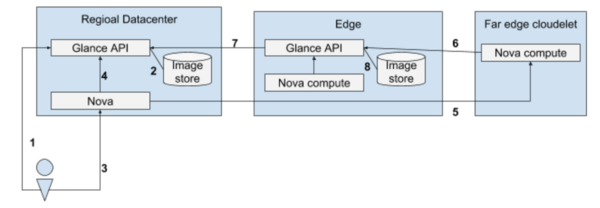
此场景展示了 Nova 在区域数据中心运行,因为在连接中断的情况下,我们不需要控制边缘站点。
- 用户将镜像上传到主数据中心的 glance
- Glance 存储镜像
- 用户调用 Nova 启动实例,传递新镜像的镜像名称或 ID
- Nova 调用主数据中心的 glance 检查镜像是否存在
- Nova 通知 nova-compute 启动实例
- Nova-compute 调用边缘站点的 glance 获取镜像
- 如果 glance 没有该镜像,它将调用主数据中心的 glance 下载镜像(转到步骤 7)
- 如果 glance 确实拥有该镜像,并且镜像的 updated_at 时间大于 glance 缓存 TTL,那么它将调用主数据中心的 glance 更新其元数据的副本(转到步骤 9)
- 如果 glance 拥有该镜像并且 updated_at 时间小于 TTL,则转到步骤 10
- 边缘数据中心的 glance 调用主数据中心的 glance 下载镜像及其元数据
- Glance 本地存储镜像
- Glance 将镜像返回给 nova-compute,实例启动
工作项
- 作为 Glance 的用户,我希望在区域数据中心上传镜像并在边缘数据中心启动该镜像。将镜像及其元数据获取到边缘数据中心。
待解决的问题
- 如果 Glance 镜像在源端更新了 - (如何) 缓存知道它需要下载新的副本?
- (长期) 如果在缓存更新期间网络失败,镜像会发生什么?它需要完全重新启动,还是可以使用 rsync 类似的增量更新?