仪器度量监控
- Launchpad 条目: NovaSpec:nova-instrumentation-metrics-monitoring
- 创建时间: 2012年10月23日
- 起草人: Tim Daly Jr, Joshua Harlow, Jeff Budzinski
- 起草人邮箱: [AT yahoo-inc.com], [AT yahoo-inc.com],[AT yahoo-inc.com]
目录
总结
为了有效地运营更大规模的 OpenStack,我们建议对处理守护进程内的关键活动进行更深入的仪器化和时序,尤其是在外部 I/O 点和关键处理流程中。这将有助于监控系统性能并在更深层次上诊断问题。建议添加一种通用的机制来测量处理和 I/O 事件以及守护进程内的其他关键指标。
发布说明
本节应包含一个段落,描述此更改对最终用户的影响。它旨在包含在首次实现此更改的发布说明中。(并非所有这些都会实际包含在发布说明中,具体由发布经理酌情决定;但编写它们是一项有用的练习。)
这是强制性的。
原理
我们的经验表明,更深层次的仪器化和监控对于跟踪规模和可用性问题、监控服务内问题、组件错误以及管理组件健康状况具有价值。
用户故事
使用此仪器化数据可以做出的示例
- 建立性能基线和验收测试的特征
- 确定各种系统组件的可扩展性特征
- 调整针对特定安装的配置参数,例如连接池、greenpools、wsgi 后端队列等。
- 针对某些类型的指标设置警报:连接池利用率、连接错误、超时
- 使用 hadoop 执行离线的大规模系统使用模式和性能分析,以进行高级调度、预测、资源平衡
度量
API 端点
- 请求接收时间
- 请求接收错误
- 请求接收超时
- 请求接收字节数
- 响应发送时间
- 响应发送错误
- 响应发送超时
- 响应发送字节数
WSGI
- 后端队列
- 等待
- 请求处理时间
- 响应处理时间
- 分发时间
事件循环
- 函数时间(原生/非原生)
- 空闲/阻塞时间
数据库
- 函数时间
- 模型查询时间
- 模型写入/更新时间
- 会话建立时间
- 连接错误
- 连接数
- ping 监听器错误
RPC
- 连接池已用
- 连接池空闲
- 消息回复时间
- 消息回复错误
- 打包上下文时间
- 解包上下文时间
- 多调用等待时间
- cast 时间
- 扇出 cast 时间
- cast 到服务器时间
- 扇出 cast 到服务器时间
- 通知发送时间
- 远程错误
- rpc 超时
Eventlet
- 池已用
- 池空闲
- greenpool 已用
- greenpool 空闲
- 等待者数量
- 超时
需求/约束
- 无论激活与否,该解决方案都应增加最少的开销。
- 该解决方案绝不能与命令和控制消息优先级竞争
- 数据的发射和收集应与现有代理兼容,并在可行的情况下可插拔。
- 聚合/关联应与数据发射分离。应支持不同的收集和分析偏好。
- 数据传输是尽力而为的,在某些情况下可以容忍丢失。
- 希望具有不同的仪器化级别,因为有些人不想深入到其他人那么深
- 希望能够按“维度”聚合统计信息,例如区域、区域、租户等。
- 我们不希望此数据通过 RPC 传输,因为它绝不能干扰或争夺 RPC 驱动操作的资源。
设计
当前计划是
- 创建一组装饰器来包装函数,用于测量执行时间、发射数字计数和原始事件。
- 扩展 nova 日志记录器以创建不同的日志级别和日志处理程序,以将指标转移到不同的数据接收器
- 使用装饰器为 nova 的一部分指标创建指标
- 创建一些使用 statsd 通过数据报和通过使用 hadoop 进行批量日志分析来聚合指标的示例。
我们将随着原型工作的完成,用更多细节来充实它。这是一个用于讨论的草图
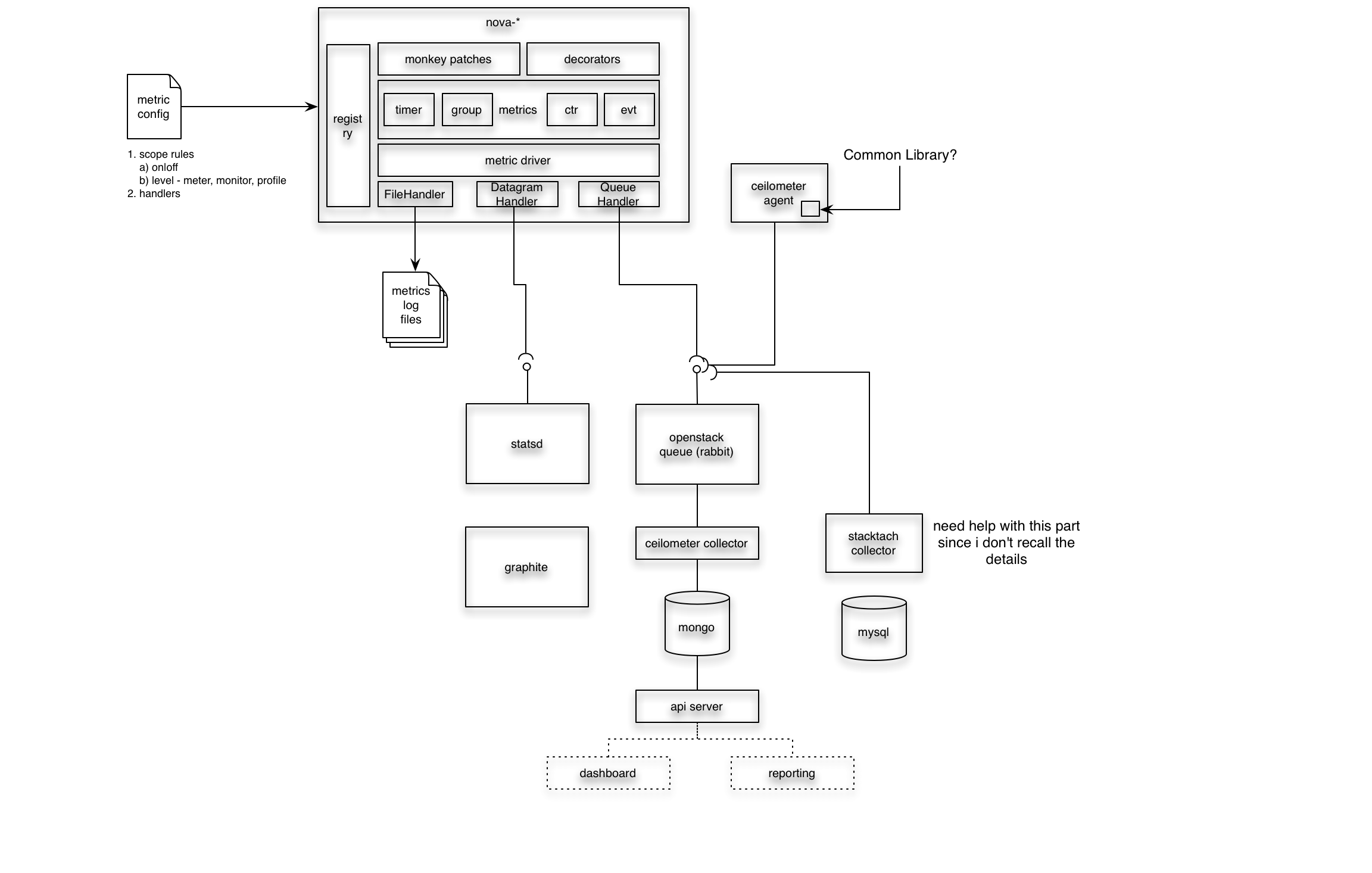
(有关 graffle 和 visio xml 版本的附件,请参见附件)
笔记
- Eventlet 后门: https://github.com/openstack/openstack-common/blob/7695f967/openstack/common/eventlet_backdoor.py
- Grizzly 设计峰会 etherpad @ https://etherpad.openstack.org/grizzly-common-instrumentation
实现
代码变更
- 为 nova/common 添加指标 gauges/decorators
- 为 nova/log.py 添加 METRIC 日志级别、指标格式、可配置的指标处理程序
- 对几个关键模块进行仪器化以开始
UI 变更
目前没有。
迁移
不适用
测试/演示计划
这不必在规范接近 Beta 之前添加或完成。
未解决的问题
- 利用 ceilometer:我们当然不希望通过 RPC 传输此数据,但可能希望利用日志代理和收集器。
- 与 stacktach 的兼容性(参见 https://github.com/rackspace/stacktach 和 http://www.sandywalsh.com/2012/09/openstack-nova-internals-pt2-services.html)
- 考虑/演进 https://blueprints.launchpad.net/nova/+spec/nova-instrumentation-v1 以及如果获得批准,受影响的代码
利用 ceilometer
- 一方面,ceilometer 正在测量的事物与监控数据之间存在明显的相似之处
- 但是,ceilometer 并非为监控而构建;它是为计量而构建的,并且不会丢失关键的计费消息
- 而且,将大量尽力而为的交付消息通过 ceilometer 和 RPC 框架发送似乎没有意义
- 是否可以使用 ceilometer 代理和服务,但使用更轻量级的传输?
利用日志记录器
- 好消息是代码已经很好地覆盖了日志记录器对象,并且我们很可能希望在许多级别进行仪器化:每请求、定期、高级、低级
- 使用指标日志适配器将仪器化数据注入日志流将相对简单
- 将添加一个过滤器以仅选择指标事件
- 可以创建一个额外的日志处理程序,以将内容从流中取出并通过网络发出,例如使用 DatagramHandler
- 待办事项:了解使用日志流的性能影响
使其开销低
- 仪器化代码在不活动时必须廉价/免费
- 可能可以通过宏或预处理来处理。虽然有点麻烦。
- 要考虑的技术
- 最深层次的仪器化可能是在 debug: 的情况下,并使用 -O 进行优化
- 不想用数据报淹没网络
- 将请求指标合并到单个事件中
- 批量发送
这与 stacktach 如何契合
- Stacktach 从 AMQP 中排队开始,这与不希望将此内容放在基于队列的 RPC 上的愿望不符
- 但是,这里存在明显的重叠,因为 stacktach 似乎被设计为收集感兴趣事物的时序。也许答案是,对于测量 RPC 流,stacktach 和仪器化不是相互排斥的?
- 关于 stacktach 的说明
- Tach - 猴子补丁库
- 使用猴子补丁以避免丑化代码
- 通过 nova.compute.queue_receive 的配置,逐方法地猴子补丁 RPC 代码?
- 仅补丁调用
- 装饰器以捕获/发出异常
- 可配置的通知器(例如 statsd)
- 本质上是包装函数并在 RPC 调用时通过 UDP 发送到 statsd
- 有另一组 stachtach 工作者监听队列并执行到 StackTach 的 REST 调用以将其插入数据库(这是 v1 实现)。开发人员的多租户。但有性能问题。
- v2 直接写入数据库,但在此基础上遇到性能问题
- django 应用程序为您提供最近活动视图(通知)
- 还有一个 cli 来查询 stacktach 的基于 REST 的 i/f
- 适合生产环境?似乎被 rackspace prod 环境使用
- 通过 uuid(很好)和也许请求 id 进行可追溯性
- 还可以获取指标:计数、最小值、最大值、平均值,用于仪器化事件(例如 compute.instance.shutdown、compute.instance.delete、compute.instance.reboot 等)
- 查看请求开始/结束请求 id 对以计算时间
- statsd 选择:超快、udp、无黑洞
会议记录
- InstrumentationMetricsMonitoring10292012 - IRC 会议记录 2012 年 10 月 29 日
相关
BoF 议程和讨论
使用本节记录 BoF 期间的笔记;如果将其保留在批准的规范中,请用于总结讨论内容并记录任何被拒绝的选项。
参见