UnifiedInstrumentationMetering
目录
统一的仪器仪表和计量
最后编辑:-- SandyWalsh
概述
有了Ceilometer、Tach 和 [[StackTach]],今天在 OpenStack 中围绕仪器仪表和计量/监控进行了一些非常棒的尝试。
然而,由于 OpenStack 内部惊人的开发速度,其中许多努力都是孤立地进行的。现在,我们正达到一个需要停止重复造轮子并就共享基础设施达成一致的成熟阶段。出于各种原因,这种需求是必要的
- 我们希望使新项目更容易地构建在现有的 OpenStack 通知消息总线上。
- 更少的代码是好事。我们不需要三个不同的工作者来提取来自 OpenStack 的通知。
- 通知量大,而且很多。我们只想处理和存储这些数据一次。
- 数据归档是一个常见的问题,我们不应该需要几种不同的方法来做到这一点。
在本文档中,我们将讨论当前 OpenStack 中仪器仪表/计量/监控 (IMM) 的现有技术以及我们可能如何发展它。
必读/观看
- https://openstack.org/summit/san-diego-2012/openstack-summit-sessions/presentation/what-about-billing-an-introduction-to-ceilometer
- http://www.sandywalsh.com/2012/10/debugging-openstack-with-stacktach-and.html
- https://etherpad.openstack.org/grizzly-common-instrumentation (关于仪器仪表需求的良好总结)
仪器仪表与计量/监控
在这个讨论的最基本层面上,需要清楚地了解仪器仪表和计量/监控之间的区别。
仪器仪表
将仪器仪表视为他们在电路中测试电子设备的方式。当设备运行时,探针连接到电路板上并进行测量。

在这个类比中需要考虑一些关键点
- 每个技术人员可能希望将他们的探针放置在不同的位置。
- 探针可以放置用于长期测量或瞬态(“我想知道……”)场景
- 电路不需要改变才能放置测试探针。没有其他组或部门参与到这种仪器仪表中。
- 相同的探针技术可以用于其他电路板。同样,我们的仪器仪表探针放置技术不应仅仅针对 Nova。它也应该适用于 OpenStack 的所有其他部分。
- 当电路改变时,我们的探针放置可能需要改变。我们必须意识到这一点。
- 探针并不完美。它们可能会滑落或连接不良。我们正在寻找趋势,识别何时出现缓慢或不稳定情况。
- 对于 Python,我们可能也对堆栈跟踪感兴趣。不仅仅是单个函数的时间/计数。
计量/监控
计量是监视系统使用情况,通常用于计费。监控是监视系统以获取关键系统变化、性能和准确性,通常用于 SLA 之类的事情。
想想你的电表。你可以走到外面看着表盘转动,并确认你的月度账单与表盘报告一致。

计量和监控的重要方面
- 这些事件/测量至关重要。我们不能冒丢失事件的风险。
- 我们需要确保这些事件在不同版本之间保持一致。它们的 consistency 与 OpenStack API consistency 同等重要。
- 我们不知道人们将如何使用这些事件,但我们可以放心地假设会有很多其他组对此感兴趣。我们不希望这些组直接与生产 OpenStack 部署进行通信。
- 这些事件可能不如仪器仪表消息频繁,但它们会更大,因为需要包含消息的整个上下文(哪个实例,哪个镜像,哪个用户等)
现有技术
那么,我们现在在哪里?
当前的仪器仪表
今天 OpenStack 没有正式的仪器仪表解决方案(除了日志记录)。日志记录不足,因为它是
- 非结构化文本
- 扫描、解析和跨服务器关联所需的精力太大
- 需要更改代码才能收集新信息
Rackspace 一直在使用 Tach、Statsd、Graphite 和 Nagios 的组合,并取得了近一年的成功。
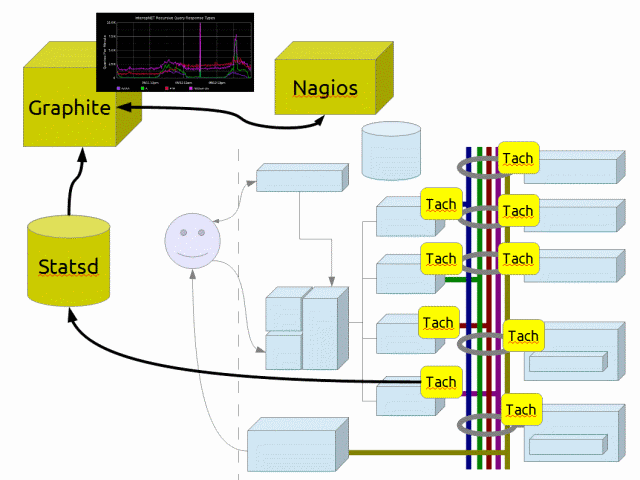
Tach 是一个从 Python 程序中的任何地方收集 timing/count 数据的库。它不特定于 OpenStack,但它具有主要 OpenStack 服务的预配置 config 文件。Tach 通过 monkey-patching 钩入编程,并具有 Metrics 和 Notifiers 的概念。Metrics 是用户可扩展的钩子,用于从代码中提取数据。Notifiers 接收收集的数据并将其发送到某个地方。当前有 Metrics 驱动程序用于执行时间和计数以及 Notifiers 用于 Statsd、Graphite 直接、print 和日志文件。(SandyWalsh 一直在开发 Tach 的替代品,称为 Scrutinize,它增加了 cProfile 支持和更简单的配置。它几乎可以投入使用了。)
Tach 的启动方式为:tach tach.conf nova-compute nova.conf ... 因此它可以轻松地集成到现有的部署中。
statsd 的强大功能是
- 基于 UDP 的消息传递,因此如果收集器崩溃,生产不会面临风险。
- 对测量值的内存 rollup/aggregate,这些测量值会转发到 Graphite。这大大提高了可扩展性。
- 用 node.js 编写 = 快,快,快。
当前的监控/计量
今天 OpenStack 中监控和计量的代表是 Ceilometer ... 我只是将您转到该项目以获取更多详细信息。
但还有其他。在 Rackspace,我们使用 YAGI 来消耗通知并将其发送到我们的内部计费系统。具体来说,此数据被发送到 AtomHopper,在那里它被转换为 Atom feed 以供其他消费者使用(其中之一是计费)。YAGI 曾经具有 PubSubHubBub 支持,但由于其他动机而已休眠。现在,AtomHopper 是首选的重新分发系统。不幸的是,AtomHopper 是基于 Java 的,因此可能不适用于 OpenStack 生态系统,从某种程度上说。YAGI Worker 使用 carrot 并且在我们的所有环境中都非常可靠,但已经讨论过迁移到 kombu。
StackTach 是一个基于 OpenStack 通知进行调试/监控的工具,它也有自己的 Worker。它是基于 kombu 的,目前正在生产中使用。我们遇到很多使 stacktach worker 可靠的问题,但我们认为问题在于将线程模型与 eventlet 结合使用。我们新的方案使用 multiprocessing 库和 per-rabbit worker。这目前正在进行压力测试,敬请期待。我们尝试了各种其他方案和库组合,但收效甚微(如果需要更多详细信息)。请注意:这应该可以正常工作,因为它与 Nova 内部使用的方案相同。
StackTach 正在快速转向 Metrics、SLA 和监控领域,版本 2 和 Stacky 的包含(StackTach 的命令行界面)
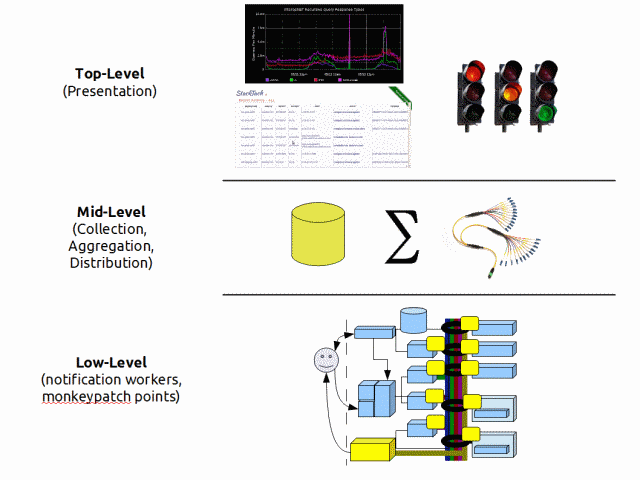
分层
在每种架构中,都有不同的抽象/功能层。
IMM 有
- 底层组件直接通过 monkeypatching 或通知消费与 OpenStack 接口。
- 中层组件收集、聚合并将收集的数据重新分发给其他消费者
- 顶层组件充当表示层。
我们目前在所有层级上都有重叠。
统一底层
在 OpenStack 内部统一仪器仪表收集与指标收集基础设施实际上是不可能的。如引言所述,这些是非常不同的动物。
对于监控和计量(通知消费),显而易见的选择是通知 worker。使用 rabbit notifier 中的队列列表不是一个解决方案,它会给 rabbit 服务器带来很大的负载。
Note: we're also using AMQP incorrectly for notifications. Events are published to an Exchange and different queues can be created for different consumers. Currently, OpenStack creates a different Exchange for each notification destination. This should simply a bug that should be fixed.
这是低垂的果实。创建一个可扩展的 worker,可以在多 rabbit(多单元、多区域)部署中工作。它应该支持可插拔的方案来处理收集的数据并支持故障转移/冗余。worker 必须足够快/可靠,才能使通知队列保持为空,因为这很容易成为增长最快的队列(与 cells capacity update 队列不相上下:)
worker 应该是一个单独的存储库,以便其他人可以独立使用它。
此外,Ceilometer worker 不需要使用所有 nova-common 代码。这是一个非常简单的程序,可以用一个文件来处理。
统一中层
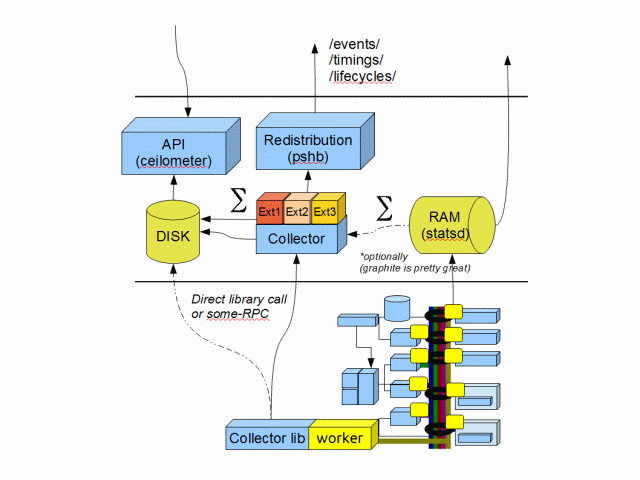
用于收集数据的通用数据库
对于计量和监控,StackTach 和 Ceilometer 都有一个数据库来存储通知。StackTach 使用基于 SQL 的数据库,而 Ceilometer 使用键值数据库 (Mongo)。每个通知都很大,包含大约十个需要快速查找的列
- 部署 ID
- 租户 ID
- UUID
- 请求 ID
- 时间戳
- 实例状态
- 实例任务
- 发布者
- 主机 ID
- 事件名称
此外,事件的整个 JSON payload 应该存储用于需要特定内容的消费者。
我没有推荐使用哪个数据库,但也许应该进行一些负载测试,看看每个数据库的表现如何。重要的是,整个事件都被存储。
但是,当这些事件被收集时,通常需要更新其他表,这些表包含来自事件的聚合/汇总信息。虽然这些操作可以在单独的数据库中批量完成,但可能更有效的是提供一种机制,以便其他应用程序可以钩入数据收集并在实时更新这些表。这是 StackTach 所做的,它大大减少了后处理需求。但是,这会增加事件存储期间的额外处理(一项昂贵的操作)。像 Ceilometer 的二次发布步骤这样的解决方案似乎很好,但我认为它应该基于 AtomHopper/PSHB 方法,而不是专有的东西。我们应该更详细地讨论重新分发系统应该是什么样子。
在上面的图中,Ext1、Ext2、Ext3 是用于执行特殊聚合工作的用户插件。(不是发送到重新分发系统,另一个插件机制可以处理它)
对于仪器仪表,如上所述,statsd 内存数据库是完美的解决方案。可能不需要对其进行改进。
通用的事件重新分发系统
如前所述,我们在内部使用 AtomHopper(以及之前带有 PSHB 的 YAGI),但使用现成的框架会很好,最好是基于 Python 的。这应该也是一个单独的存储库,并且理想情况下是可选的。
在 DreamHost 的用例中,The Dude 应该从 AtomHopper feed 基于 webhook 消费,而不是必须轮询 Ceilometer API 以获取更新。
告警/设定点/阈值
就我个人而言,我不认为这应该放在中间层……外部组件应该定义/监控/控制这些。
统一顶层
每个客户端都不同,试图用通用的用户界面来满足每个用户的需求可能很棘手。 StackTach 最初是一个调试工具,目标受众是调试人员。计费工具则需要非常不同的用户界面。
有很多现成的产品可用于呈现仪表数据,我们不需要重新发明轮子。
StackTach 和 Stacky 都应该从 Ceilometer API 获取数据。
其他改进
- 移除 Ceilometer 使用的 Compute 服务,并将现有的 fanout compute 通知整合到 worker 收集的数据中。我们不需要再多一个 worker。话虽如此,我相信某些部署肯定会有一些未被涵盖的特定需求,现有的 Ceilometer 收集器系统仍然会需要。
- StackTach 在优化其 REST 接口以方便缓存方面取得了重大进展。中间层的数据很大程度上是只读的,并且读者远多于写者。Ceilometer API 应该考虑这些改进(如果尚未处理,并且我遗漏了的话)。