已废弃:Swift-Improved-Object-Replicator
- Launchpad Cinder 蓝图: improved-object-replicator
- 创建时间: 2012年10月2日
- 上次更新时间: 2012年10月2日
- 起草人: Alex Yang Hui Cheng
- 贡献者: Alex Yang Hui Cheng
目录
摘要
本蓝图的目标是提高对象复制器的效率。在Swift中,对象复制器在保持数据一致性和数据持久性方面发挥着重要作用。但是,对于数十亿对象的生产环境,由于同步数据阶段耗时,对象复制器的性能并不理想。此外,在发生故障期间,同步数据的时间会影响数据持久性和数据一致性。因此,优化对象复制器的机制是必要的。
本蓝图讨论了对象复制器的当前实现和性能问题,以及如何在新的对象复制器中解决这些问题。
当前对象复制器的实现
作为一个类似 Dynamo 的存储系统,复制器的主要任务如下
副本同步:一种反熵协议,用于保持副本的一致性和副本恢复。提示切换恢复:为了确保由于临时节点或网络故障而不会导致读写操作失败,当原始节点不可用时,临时节点会成为切换节点。因此,在原始节点可用后,副本应从切换节点移动到原始节点。
在 Swift 中,对象复制器负责副本同步、提示切换恢复和目录回收。对象复制器的主要逻辑如下所示
01: partitions = collect_partitions() 02: # collect jobs 03: for partition in partitions: 04: if partition not in local: 05: partitions_to_move.add(partition) 06: else: 07: partitions_to_check.add(partition) 08: # hinted handoff recovery 09: for partition in partitions_to_move: 10: move_to_origin_node(partiotion) 11: # replica synchronization 12: for partition in partitions_to_check: 13: local_hash_of_suffix_dirs = get_hashes_and_reclaim(partition) 14: remote_hash_of_suffix_dirs = get_reomote_hashes(partition) 15: different_suffix_dirs = compare(local_hash_of_suffix_dirs, remote_hash_of suffix_dirs) 16: rsync(different_suffix_dirs)
当前对象复制器的不足
一轮复制耗时过长
对于我的 Swift 部署,一台服务器上有大约 150,000 个分区和 30,000,000 个后缀目录。磁盘使用率百分比为 12%(约 2T)。在一般情况下,一轮复制需要 15 小时。如果有节点故障,则需要更多时间。随着对象数量的增加,复制时间会越来越长。对于数据一致性和持久性来说,复制时间过长是不可接受的。即使我们可以添加更多节点来缩短时间,我们也会考虑投资回报率。
对象复制器灵活性不足
一轮复制会循环磁盘上的所有分区并随机同步它们。因此,如果有一些紧急副本需要同步,当前机制无法尽快同步它们。
设计原则
- 将同步过程拆分为异步;
- 实时计算复制的哈希值;
- 与当前对象复制器兼容;
- 复制过程可控;
实现
设计将分为两部分描述。首先,一个图显示了整体架构;其次,将详细讨论该架构的组件。
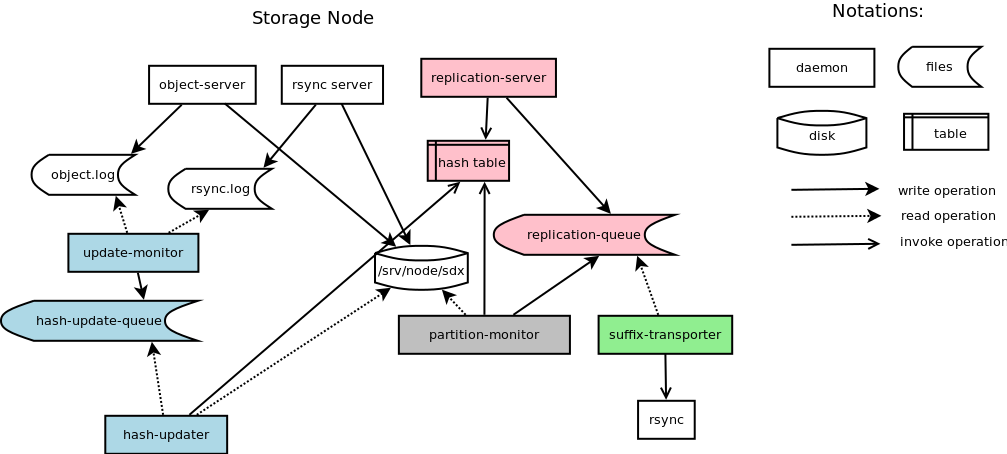
如图所示,带有颜色的图标是此设计的主要组件。它们都与当前对象复制器独立。对象复制器的原始逻辑被拆分为四个部分,分别用不同的颜色表示。颜色为青色的组件负责实时计算哈希值;颜色为粉色的组件负责索引后缀和分区目录的哈希值,接收和发送请求以比较分区或后缀的哈希值,生成将后缀目录复制到复制队列的作业;分区监视器负责以间隔检查分区是否需要移动;后缀传输器负责监视复制队列并调用 rsync 来同步后缀目录。
实时计算哈希值
update-monitor
更新监视器负责监视对象服务器和 rsync 服务器的日志文件。PUT 和 DELETE 操作的日志将被 update-monitor 过滤并放入 hash-update-queue 中。
hash-update-queue
一个用于存储 update-monitor 数据的队列。
hash-updater
一个守护进程,用于计算 hash-update-queue 中的后缀目录的哈希值并将其更新到哈希表中。
== 哈希表 == 哈希表是一种键值存储,用于存储一个磁盘上的 {partition/suffix: hash} 和 {partition: hash} 项目。{partition/suffix: hash} 与分区目录下的 hashes.pkl 文件相同。{partition: hash} 是所有 {partition/suffix: hash} 的 MD5 校验和。结构如下所示。
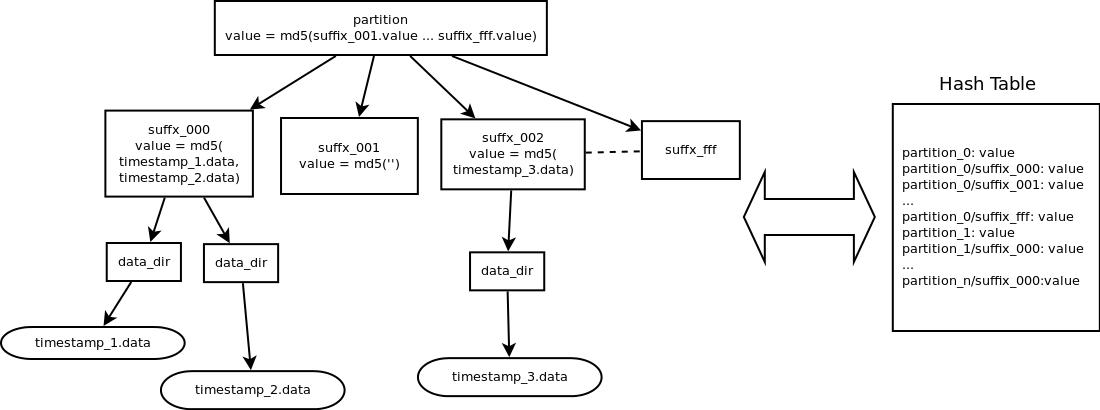
哈希表中的项目总数将达到一亿。我们可以使用以下公式计算近似的项目数。
item_num ~= (partition_num * replica_num * suffix_num + partition_num * replica_num) / disk_num;<
> item_num ~= partition_num * replica_num * (1 + suffix_num) / disk_num<
> 因为最大后缀数 = 16^3 = 4096,所以:<
> item_num ~= partition_num * replica_num * 4097 / disk_num<
>
在本公式中,我们认为磁盘的权重都相同。item_num 可能很大或很小。它取决于 partition_num、replica_num 和 disk_num 的配置。例如,如果分区数为 218,replica_num 为 3 且 disk_num 为 50,则 item_num ~= 218 * 3 * 4097 / 50 ~= 64440238。
考虑到哈希表的大小,我们不能将所有哈希表存储在内存中。我们必须将哈希表存储在磁盘上并在内存中缓存部分数据。因此,我们使用 LSM-Tree 和 bloom 过滤器来实现此目标。LSM-Tree,Log-Structured Merge-Tree,是一种基于磁盘的数据结构,旨在为经历长时间高记录插入(和删除)速率的文件提供低成本索引。Bloom 过滤器是一种空间高效的概率数据结构,用于测试一个元素是否是集合的成员。LSM-Tree 和 bloom 过滤器的集成可以提供高性能的写入和读取操作。有一些开源项目实现了 LSM-Tree 和 bloom 过滤器,例如 leveldb 和 nessDB。我们可以使用其中一个来存储哈希表。
Replication-Server
Replication-server 是一个 REST-API 服务器,用于接收来自对等节点或控制节点的请求。来自对等节点的请求是比较一个分区的哈希值,如果本地分区的哈希值与远程哈希值不同,则 replication-server 将返回所有后缀目录的哈希值作为响应。来自控制节点的请求是同步特定的分区或后缀目录。因此,replication-server 应该处理这种类型的请求并生成作业到 replication-queue。例如,在重新平衡环之后,有一些分区需要传输,传输一个分区可以拆分为不同的节点执行的多个后缀传输部分。
Partition-Monitor
Partition-monitor 是一个以间隔运行的守护进程。Partition-monitor 的主要任务如下所示
- 收集需要移动的分区并将它们放入 replication-queue。
Partition-monitor 将磁盘上的所有分区与环进行比较。如果分区是 handoff 或需要传输,partition-monitor 将将其添加到 replication-queue。
- 向对等节点的 replication-server 发送请求以比较哈希值,如果它们不同,则将其放入 replication-queue。
这里可以使用优先级队列。Partition-monitor 首先比较最活跃的分区。
Suffix-Transporter
一个守护进程,用于执行 replication-queue 中的作业。
总结
本蓝图的原则是将对象复制器的同步过程拆分为异步。通过进行此更改,复制可以更加灵活和可控。特定的 replication-server 可以拆分来自对象服务器的 REPLICATE 请求并接收来自控制节点的请求。可以在 hash-update-queue 和 replication-queue 中使用一些策略来控制复制。所有这些都基于 Dynamo 的论文并与对象复制器兼容。