已废弃:概述
集群、全球化和横向扩展架构概述
此页面用于讨论 2010 年 8 月在第一次 OpenStack 设计峰会上提出的整体架构,因此此处讨论的内容可能已过时。更准确的信息可以在 Nova 开发人员站点,服务架构 和 Swift 开发人员站点,架构概述 上找到。
此主题的实时记录可以在这里找到:http://etherpad.openstack.org/Clustering
以下部分描述了两种提议的分布式架构。第一种使用分层方法,第二种使用对等方法。
术语表
- 公共 API 服务器 - 在 Cloud Servers v1 中称为“核心”,在其他系统中称为“云控制器”。
- 集群 - 一组物理主机节点。在 Cloud Servers v1 中称为“聚会”。
- 集群控制器 - 在每个集群上运行的软件,用于控制其中的主机。在 Cloud Servers v1 中称为“QB”。
- 主机 - 集群中的单个物理主机。
- 客户 - 在主机上运行的虚拟机实例。
通用组件
所有绿色框代表我们需要编写或使用现成软件的部分。例如,消息队列可能是 Rabbit MQ,但我们很可能需要编写我们自己的主机和客户代理。所有红色框代表某种形式的数据存储,无论是简单的内存键/值缓存还是关系数据库。存储在集群控制器和公共 API 服务器中的数据很可能是主机表数据的缓存,这些数据需要用于做出明智的决策,例如将 API 请求路由到何处或安排新的操作。
请注意,只有集群控制器通过消息队列与公共 API 服务器通信,主机和客户代理绝不应直接与 API 服务器通信。应尽可能使用这种连接聚合(客户->主机,主机->集群控制器,集群控制器->公共 API 服务器)。
镜像缓存和源很可能利用现有的技术,例如 ibacks 和 Cloud Files,但它应该保持通用,以便支持其他(可能来自外部)镜像源。例如,用户可能希望指定一个任意 URI 来拉取自定义镜像。
分层结构
从高层来看,这种方法类似于 DNS 的工作方式,集群控制器会向一组公共 API 服务器注册,并且进入这些 API 服务器的请求会路由到适当的集群(或多播到多个集群)以回答查询。根据我们可以在该层有效缓存来自集群的数据量,我们应该能够直接回答一些子集的查询,而无需转发到集群。这允许集群控制器充当集群内所有主机的聚合层,因此只有 2-3 个集群控制器需要向公共 API 服务器注册(而不是每个主机)。这种架构至少需要四个逻辑 API,但它们在实现中可以共享代码。这些是
- 外部用户到公共 API 服务器
- 公共 API 服务器到集群控制器
- 集群控制器到主机
- 主机到客户代理。
如果信息可用且最新,则可以在任何层回答请求。在简单的单集群设置中,您可以将公共 API 服务器与集群控制器一起启动。
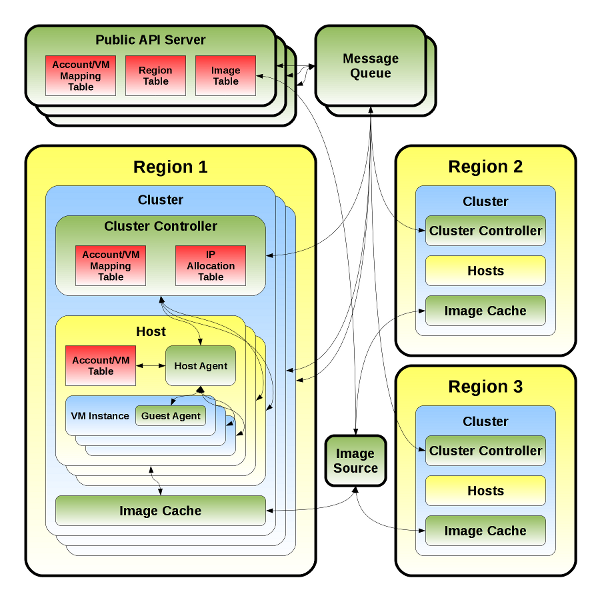 原始 Open Office Draw 文件可以在这里找到:attachment:cloud_servers_v2.odg
原始 Open Office Draw 文件可以在这里找到:attachment:cloud_servers_v2.odg
对等网络
对等模型看起来更像是 SMTP、IRC,甚至某些网络路由协议(BGP、RIP 等)。这将允许集群控制器相互对等,并且他们将通过聚合资源通知来通告本地或对其其他对等方可用的资源。集群图不需要完整(完全连接),它可以松散连接。公共 API 服务器和集群控制器在功能上是逻辑上分开的,但可以合并到同一软件中。这种组合将同时使用公共 API 和对等 API,并且可以直接回答请求或将其路由到可以回答它的集群。这可能采取代理请求或重定向的形式。例如,如果请求作为 HTTP 请求传入,则可以发送带有适当集群以联系的 301 或 302 重定向响应。
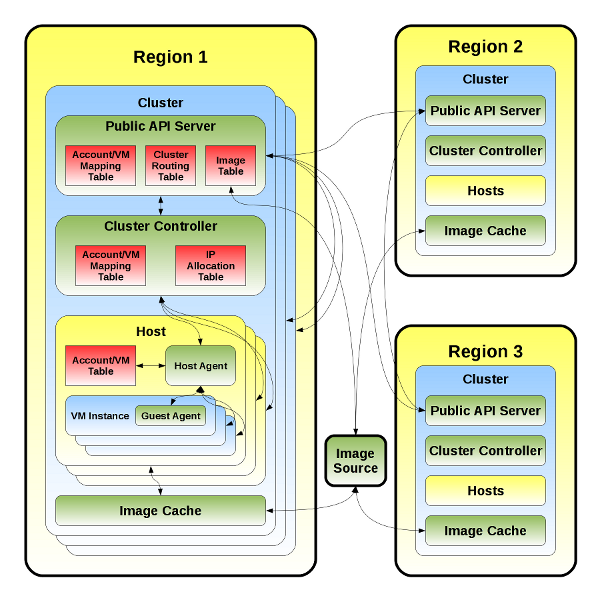 原始 Open Office Draw 文件可以在这里找到:attachment:cloud_servers_v2_peer.odg
原始 Open Office Draw 文件可以在这里找到:attachment:cloud_servers_v2_peer.odg